


一. CDC是什么
CDC是Chanage Data Capture(数据变更捕获)的简称。其核心原理就是监测并捕获数据库的变动(例如增删改),将这些变更按照发生顺序捕获,将捕获到的数据,写入数据库种如神策数据的核心kudu、doris、mysql、kakfa等。
二. CDC的实现方式2.1 基于查询的CDC
离线调度查询作业,批处理。把一张表同步到其他系统,每次通过查询去获取表中最新的数据
无法保障数据一致性,查的过程中有可能数据已经发生了多次变更;
不保障实时性,基于离线调度存在天然的延迟。
2.2 基于日志的CDC
实时消费日志,流处理,例如 MySQL 的 binlog 日志完整记录了数据库中的变更,可以把 binlog 文件当作流的数据源;
保障数据一致性,因为 binlog 文件包含了所有历史变更明细;
保障实时性,因为类似 binlog 的日志文件是可以流式消费的,提供的是实时数据。
三. 开源CDC工具对比
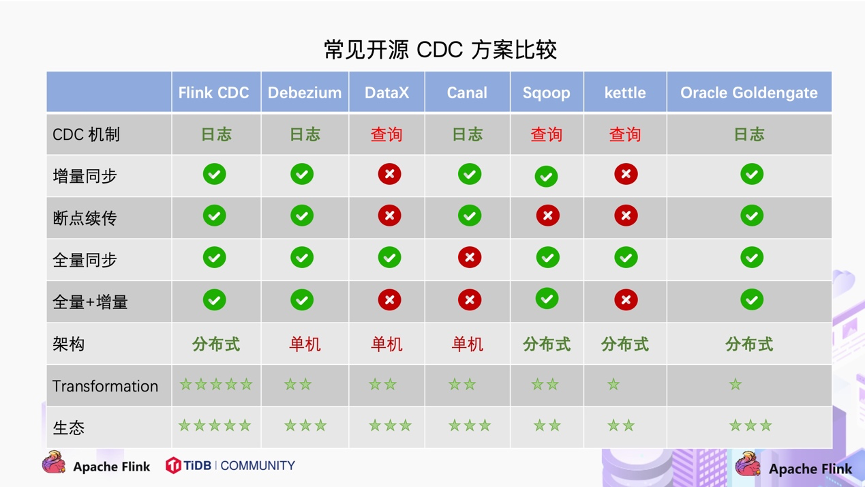
从上图可知:
基于日志的CDC机制,除Canal都可以很好的做到增量同步。
基于查询的CDC机制,增量和断点几乎都不支持,除Sqoop支持增量方式。
从全量同步维度看,除Canal不支持全量同步,其它的CDC都支持。
从全量+增量角度看,基于日志方式的CDC都是支持的。
从架构角度去看,该表将架构分为单机和分布式,这里的分布式架构不单纯体现在数据读取能力的水平扩展上,更重要的是在大数据场景下分布式系统接入能力。例如 Flink CDC 的数据入湖或者入仓的时候,下游通常是分布式的系统,如 Hive、HDFS、Iceberg、Hudi 等,那么从对接入分布式系统能力上看,Flink CDC 的架构能够很好地接入此类系统。
在数据转换 / 数据清洗能力上,当数据进入到 CDC 工具的时候是否能较方便的对数据做一些过滤或者清洗,甚至聚合?
在 Flink CDC 上操作相当简单,可以通过 Flink SQL 去操作这些数据;
像 DataX、Debezium 等则需要通过脚本或者模板去做,所以用户的使用门槛会比较高。
在生态方面,这里指的是下游的一些数据库或者数据源的支持。Flink CDC 下游有丰富的 Connector,例如写入到 TiDB、MySQL、Pg、HBase、Kafka、ClickHouse 等常见的一些系统,也支持各种自定义 connector。
