


前言
Append模式每次都生成新的parquet文件,不涉及数据修改、去重。cow+insert一直是append模式,mor+insert在0.13.1后也统一走append写流程(HUDI-6045)
在0.13.1之前,mor+insert存在着写parquet和写log两种情况:
- 写parquet:compaction.schedule.enabled = false & clustering.async.enabled = true,这时是append模式
- 写log:compaction.schedule.enabled = true & clustering.async.enabled = false,这时走upsert写过程
append写过程比upsert简单直接得多,因此写入性能远优于upsert.
整体流程

- 与upsert写过程一样,借助StreamWriteOperatorCoordinator作为写协作器,协调各个write task,负责初始化和推进instant、调度compaction和clustering、同步hive
- checkpoint或数据大小到达阀值会触发刷盘,并滚动创建新的文件。
- 重用了bulk_insert的核心类BulkInsertWriterHelper,insert和bulk_insert高度相似。
AppendWriteFunction
- 以Pipelines#append为入口,算子名称为hoodie_append_write,写并行度配置保持一致write.tasks,只不过相对于旧版本去掉了默认值4所以建议显式指定该配置值,否则将跟随flink环境默认并行度。
- 所有接收到的数据交由BulkInsertWriterHelper处理
- 每次checkpoint时会进行flushData,同时将BulkInsertWriterHelper重置,即将会生成新的fileId的数据文件。
BulkInsertWriterHelper
一个write task对应一个BulkInsertWriterHelper
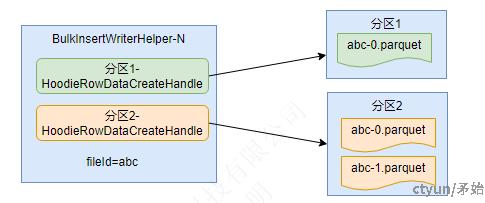
- 每个BulkInsertWriterHelper对象有唯一fileId,checkpoint会生成新的
- 不同分区的数据由不同的HoodieRowDataCreateHandle处理
- 在一个ckeckpoint间隔内,如果HoodieRowDataCreateHandle处理的数据量 > maxFileSize时,滚动创建新parquet文件,但是fileId相同。
maxFileSize = hoodie.parquet.max.file.size + hoodie.parquet.max.file.size * hoodie.parquet.compression.ratio
调用栈
write:86, ParquetRowDataWriter write:62, RowDataParquetWriteSupport write:36, RowDataParquetWriteSupport write:138, InternalParquetRecordWriter write:310, ParquetWriter writeRow:65, HoodieRowDataParquetWriter write:131, HoodieRowDataCreateHandle write:113, BulkInsertWriterHelper processElement:86, AppendWriteFunction
追加模式持续创建新的文件,特别是数据吞吐量不大的时候,将会产生大量小文件,无论对查询还是文件系统都会增加很大压力,所以需要配合clustering服务、clean服务来进行优化。
