


Kubernetes 是容器编排引擎,用来对容器进行自动化部署、扩缩和管理。Kubernetes 更像是一个对资源进行管理和分配的系统,只负责把工作负载进行合理调度,最大化利用集群资源。
在实践中 Kubernetes 集群往往是部署很多套的,不同的业务线、不同部门或子公司都是使用的独立的集群,甚至常见的同一个服务会部署在不同区域的集群中以实现用户就近服务。要想实现将服务同时部署到多个集群单纯靠 Kubernetes 是不行的。严格来讲,在 Kubernetes 中是没有这里所说的应用这个维度的。
在应用的整个生命周期中,应用是可以存在多个集群,多个环境的。如在开发中可以把应用部署在开发测试集群,在上线后可以同时部署到生产和容灾集群,这很显然是一种超越 Kubernetes 集群的概念。
由于 Kubernetes 无法完成对应用的管理,所以业界诞生了多种方案来解决应用管理的需求,常见的有 OCM、Karmada 和 KubeVela,本文将对这几种方案进行总体介绍并基于使用需求进行选型。
Open Cluster Management(OCM)
Open Cluster Management (OCM) 是用于 Kubernetes 多集群编排的一个功能强大,模块化,可扩展的平台。
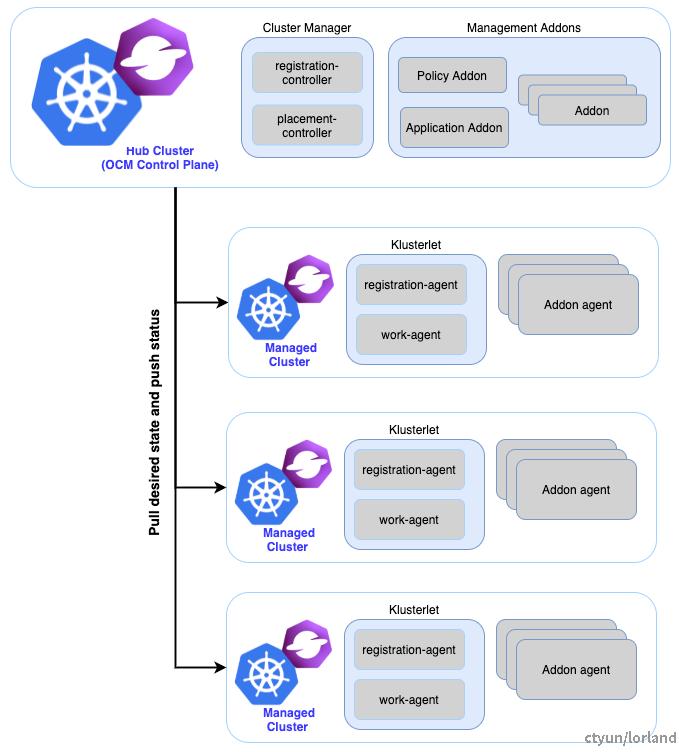
在 OCM 中,多集群控制平面,被直观的建模为 Hub,而相对的,每一个被 Hub 管理的集群则为 Klusterlet:
- Hub Cluster:表示运行着 OCM 多集群控制平面的集群。通常 hub cluster 应该是一个轻量级的 Kubernetes 集群,仅仅托管着一些基础的控制器和服务。
- Klusterlet:表示由 hub cluster 管理着的集群,也被称为
managed cluster或spoke cluster。klusterlet 主动的从 hub cluster拉取最新的指令配置,并持续将 Kubernetes 集群调和到预期状态。
这样的设计受 kubelet 和 apiserver 的启发,klusterlet 的名字就来自 kubelet。
在这种架构的设计之下,hub 并不会直接请求实际集群,而是以声明式的方式维护每个集群的处方,由 klusterlet 主动从 hub 拉取指令并执行。
OCM 架构示意图
上图中的组件:
- registration 负责集群注册、集群生命周期管理、管理插件的注册和生命周期管理;
- work 负责资源的分发;
- placement 负责集群负载的调度。
OCM 提供了丰富的多集群负责调度策略和可靠的资源分发引擎,可以让托管集群连接到集群的控制平面,甚至这些托管的集群并不能被控制平面直接访问到。它特别能处理托管集群和控制平面处于不同 VPC 的情况。
得益于 OCM 的 hub-agent 架构
OCM 还能与 KubeVela 等结合使用,提供集群管理功能。
使用 OCM 部署应用
在 OCM 中使用 ManifestWork CRD 来部署资源,如部署 Deployment:
1 |
apiVersion: work.open-cluster-management.io/v1
|
OCM 访问纳管集群
OCM 使用拉模式管理的集群,但在一些特定时候就有从 Hub 集群访问纳管集群的需求,这时需要有一个访问的方法。在 OCM 中使用 Cluster Proxy(Apiserver-Network-Proxy) 和 Cluster Gateway 实现。
对于处在不同 VPC 中的纳管集群,Hub 到纳管集群的网络可能是不通的,而纳管集群到 Hub 可以连通。在 OCM 中可以安装 Cluster Proxy 打通 Hub 到纳管集群的网络连接。示意图如下:
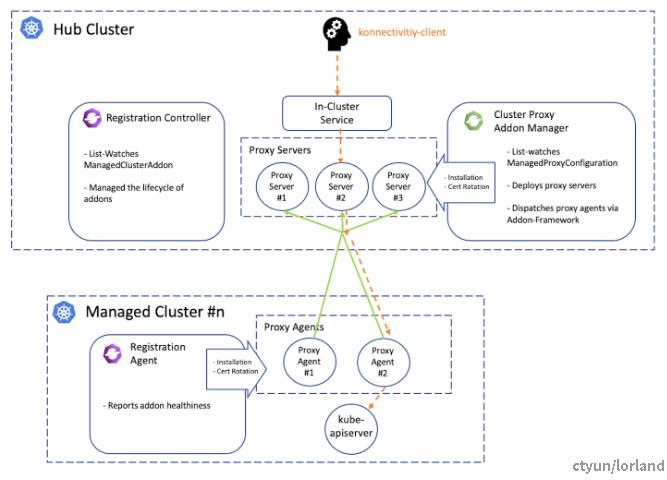
Cluster Proxy
当需要从 Hub 集群主动访问纳管集群时,使用 Cluster Gateway 组件来实现,此时如果 Hub 到纳管集群能连通会使用直连的方式代理,否则走 Tunnel 去访问,示意如图:
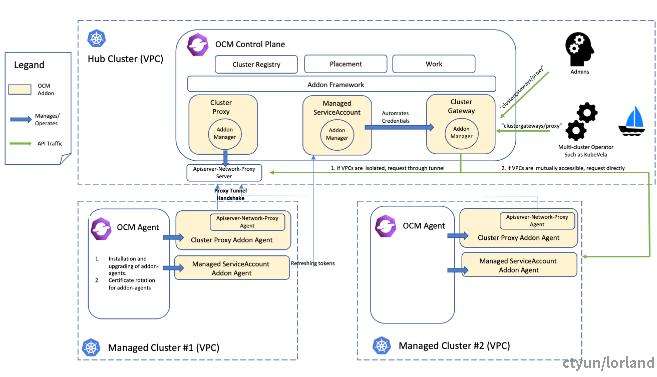
Cluster Gateway
Cluster Gateway 使用的是 KubeVela 的 Cluster Gateway 组件,实现原理在介绍 KubeVela 的时候我们再讨论。
Karmada
Karmada(Kubernetes Armada)基于 Kubernetes Federation v1 和 v2 开发,是一个 Kubernetes 管理系统,一个 kubernetes 多集群管理的插件,运行在 kubernetes 集群里,可让跨多个 Kubernetes 集群和云运行云原生应用程序,而无需更改应用程序。
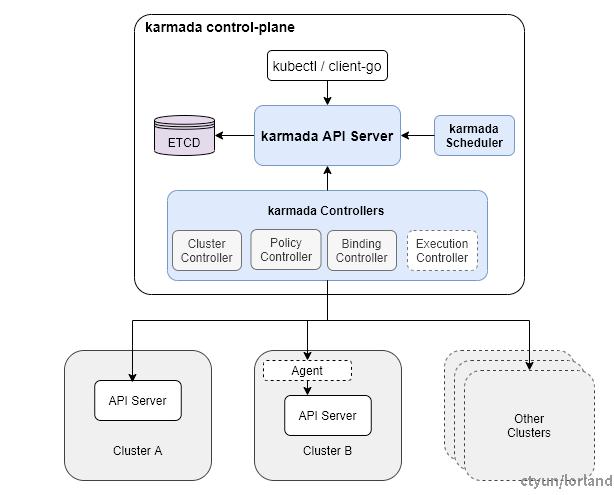
Karmada 架构图
Karmada 通过独立的 API 服务器(Karmada API Server)提供与其他组件进行通信的 REST 接口,包含 Kubernetes 原生 API 及 Karmada 扩展 API。纳管集群支持 Push 和 Pull 模式。
Karmada 调度器则实现应用在多集群中的调度。
Karmada 控制器运行各种控制器,控制器监视 Karmada 的对象,然后与底层集群的 API 服务器通信,对 Kubernetes 资源进行全生命周期管理。
- Cluster Controller:集群管理,将 Kubernetes 集群附加到 Karmada,通过创建集群对象(Cluster)管理集群的生命周期;
- Policy Controller:实现 PropagationPolicy 对象的生命周期。根据 PropagationPolicy 中的 resourceSelector 匹配对应 Kubernetes 资源对象,并为创建 ResourceBinding 以进行应用多集群调度;
- Binding Controller:实现 ResourceBinding 对象的生命周期,根据调度器的结果,为每个调度到目标集群的对应资源创建 Work 对象;
- Execution Controller:负责 Work 对象与成员集群中实际资源对象的状态同步。
Karmada 处理流程:
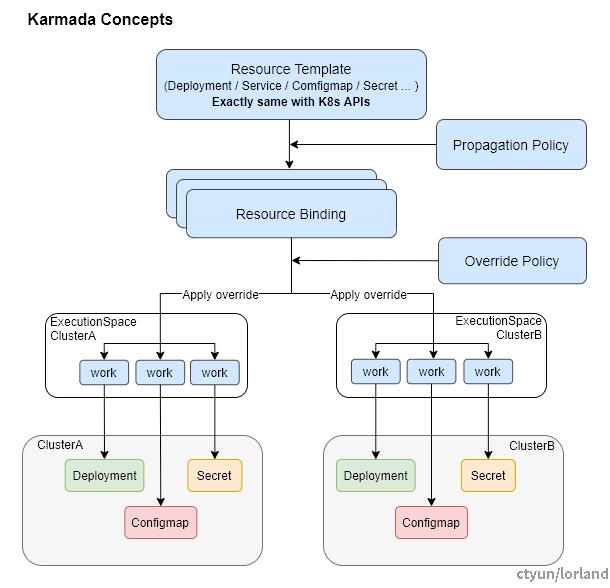
Karmada 处理流程
使用 Karmada 部署应用
在 Karmada 中直接使用原生 Kubernetes 的方式就可以部署资源,比如部署 nginx 的 Deployment:
1 |
apiVersion: apps/v1
|
注意,部署时需要使用 Karmada 的 Apiserver,并且要实现调度控制需要另外创建 PropagationPolicy 来进行。
Karmada 访问纳管集群
Karmada 在使用 PULL 模式管理纳管集群时也可以使用 ANP(Apiserver-Network-Proxy)进行代理,也提供了和 Cluster Gateway 一样使用 AA(apiserver-aggregation)来实现 apiserver 代理的能力,可以将 API 请求转发到后端纳管集群。
路径格式如下:
1
|
/apis/cluster.karmada.io/v1alpha1/clusters/{clusterName}/proxy/api/v1/pods
|
路径分为三个部分:
- karmada 固定部分:
/apis/cluster.karmada.io/v1alpha1/clusters/ - 指定目标集群:
{clusterName}替换成自己需要的集群名 - Kubernetes 真实请求 API:
/proxy后面部分,上例中是/api/v1/pods
KubeVela
KubeVela 是基于 Kubernetes 的混合云应用交付和管理控制平面,它以 CRD 控制器的形式运行,可以很轻量的安装到企业现有的 PaaS 体系中,并带来 OAM 的标准化模型和基于模型高可扩展功能的丰富社区插件。
KubeVela 的核心是将应用部署所需的所有组件和各项运维动作,描述为一个统一的、与基础设施无关的“部署计划”。
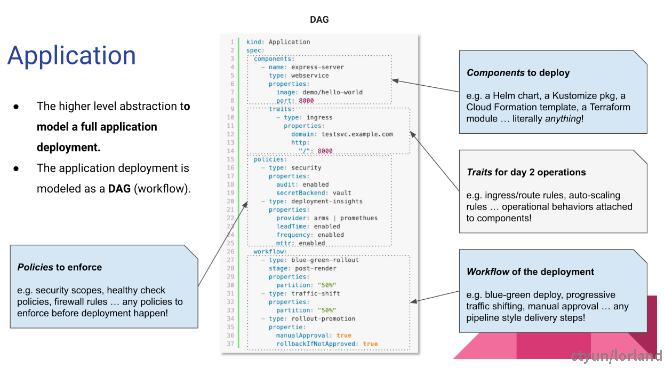
DAG
每一个应用部署计划都由四个部分组成,分别是组件、运维能力、部署策略和工作流:
- 组件(Component): 组件定义一个应用包含的待交付制品(二进制、Docker 镜像、Helm Chart…)或云服务(一个应用部署计划部署的是一个微服务单元);
- 运维特征(Trait): 运维特征是可以随时绑定给待部署组件的、模块化、可拔插的运维能力,比如:副本数调整(手动、自动)、数据持久化、 设置网关策略、自动设置 DNS 解析等;
- 应用策略(Policy): 应用策略负责定义指定应用交付过程中的策略,比如多集群部署的差异化配置、资源放置策略、安全组策略、防火墙规则、SLO 目标等;
- 工作流步骤(Workflow Step): 工作流由多个步骤组成,允许用户自定义应用在某个环境的交付过程。典型的工作流步骤包括人工审核、数据传递、多集群发布、通知等。
下图为多集群应用的整体结构图。如图所示,所有的配置信息(包括应用、策略和工作流)都处于管控集群中。只有资源(如 deployment 或者 service)会被下发到子集群之中。
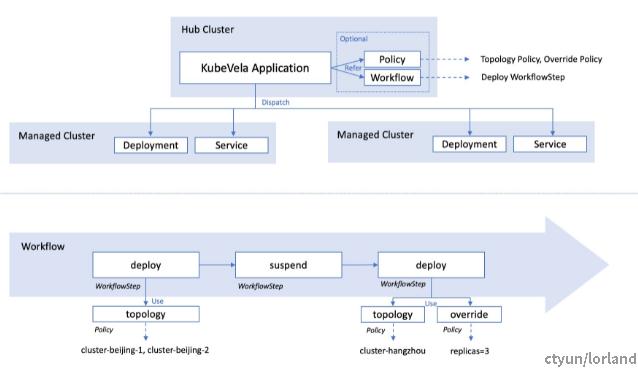
应用结构图
架构
在架构上,KubeVela 只有一个 controller 并且以插件的方式运行在 Kubernetes 之上,交付的应用部署在纳管集群中,为 Kubernetes 带来了面向应用层的抽象。
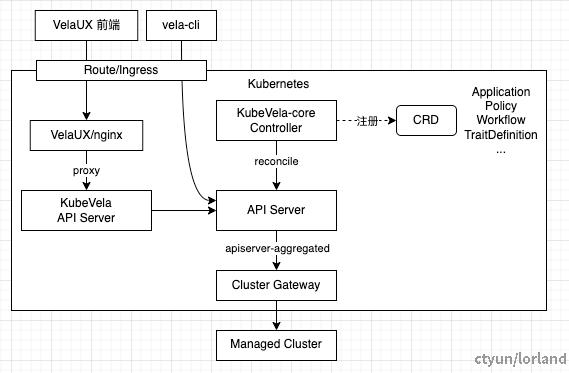
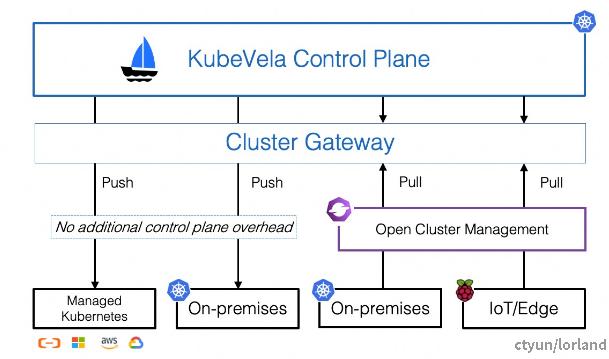
部署架构
当使用 KubeVela 交付应用时,最终应用信息会以 CRD 的形式存储在 Kubernetes 集群中。Controller 在 CRD 的控制循环中,通过内嵌的工作流组件执行应用的 Workflow 实现应用交付。
KubeVela 操作纳管集群时需要通过 Cluster Gateway 组件进行,并不直接访问目标集群。集群信息在注册集群时会保存在对应的 Secret 配置中,Cluster Gateway 在代理时使用这些信息进行访问。
使用 KubeVela 部署应用
部署资源使用 OAM 应用定义的配置文件。
这里是一个包括了一个无状态服务组件和运维特征,三个部署策略和工作流步骤的配置示例。含义是:
- 将一个服务部署到两个目标命名空间;
- 在第一个目标部署完成后等待人工审核;
- 人工审核后部署到第二个目标,且在第二个目标时部署 2 个实例。
1 |
apiVersion: core.oam.dev/v1beta1
|
KubeVela 访问纳管集群
KubeVela 的多集群依赖于 Cluster-Gateway 组件,在安装 KubeVela 的 Helm Chart 中一同安装。
Cluster Gateway
KubeVela 纳管集群时,将 kubeconfig 信息存储到 Secret 中,可以纳管原生集群,也可以接入 OCM 来使用拉取(PULL)模式来管理某些特殊集群。
Cluster-Gateway 使用 apiserver 原生扩展接口 apiserver-aggregation 实现的代理功能。
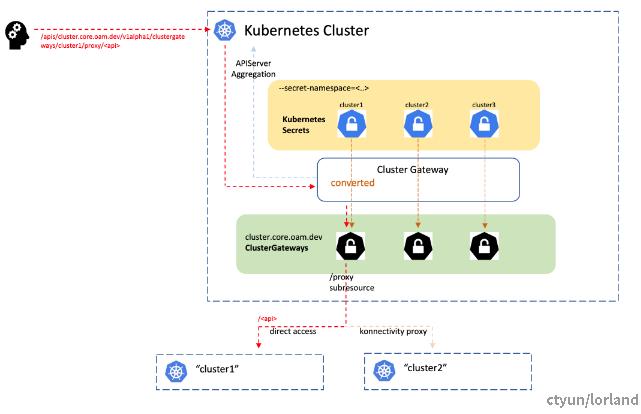
Cluster Gateway 处理流程图
代理访问的路径格式如下:
1
|
/apis/cluster.core.oam.dev/v1alpha1/clustergateways/{clusterName}/proxy/{api}
|
转发到纳管集群的 Apiserver 前,认证信息会使用集群名字对应的 Secret 里配置的信息进行替换。Secret 配置样例如下:
1 |
apiVersion: v1
|
选型思考
三种方案都能满足跨集群应用管理的功能需求,所以选型时主要基于应用部署方式、部署架构、集群代理方式、维护难度和扩展性进行考虑,这几种方案对比如下:
| KubeVela | Karmada | OCM | |
|---|---|---|---|
| 应用部署 | CRD 部署 | 原生 | CRD 部署 |
| 部署架构 | 单 Controller | 自定义的 apiserver,Scheduler, Controller 等 | 多个 Controller + 纳管集群的 Agent |
| 集群代理 | Cluster Gateway | karmada-aggregated-apiserver | Cluster Gateway+Cluster Proxy |
| 维护难度 | 易 | 难 | 中 |
| 扩展性 | 灵活 | 灵活 | 灵活 |
| 社区活跃 | 活跃 | 活跃 | 不太活跃 |
karmada 虽然不需要使用自定义的 CRD 方式进行应用部署,能减少迁移的成本,但需要使用 karmada 修改后的 apiserver 和调度器,架构的维护难度更大,且对于使用 OCP(OpenShift Container Platform) 等集群后续升级兼容等难以支持。
OCM 相对 karmada 来说部署架构简单了许多,其架构是 PULL 模式,Agent 需要连接 Hub 拉取部署配置。有些公司的网络结构不支持,比如我所在公司。现在社区也不够活跃,文档也比较少。
KubeVela 相对 OCM 在部署架构上更进一步,只有一个 Controller 负责应用的策略调度下发等功能,集群管理时只通过 Cluster Gateway 进行访问,只需要做一些适配开发就可以支持管理集群中的应用。
所以综合考虑,KubeVela 更适合目前的需要,同时灵活的扩展支持也能为以后的需求提供持久保障。
