



为了验证PXC集群的故障和容灾恢复能力,在三个网络和电力相互隔离的可用区(A,B,C)中各部署了一个PXC节点(node1,node2,node3)共同组成PXC集群。且为每个可用区中的PXC节点设置了自动重启执行脚本,即当每分钟如果监听到端口未被占用时,重新拉起PXC节点。
容灾测试时,对可用区A进行全部宕机操作,然后再进行重启。发现故障:
1. 可用区A中的自动重启脚本定时执行,但node1节点并未成功加入集群,而是不断尝试加入。
2. 集群中剩余的两个可用区的PXC节点本应使得集群提供持续的正常服务,但实际上集群状态在可用和不可用之间反复横跳,影响集群可用性。
解决:
起初怀疑node2和node3节点之间的网络波动问题,但PXC集群允许的最大时延为PT3S,不应该出现。
停止node1的重启,集群状态可提供持续的正常服务。
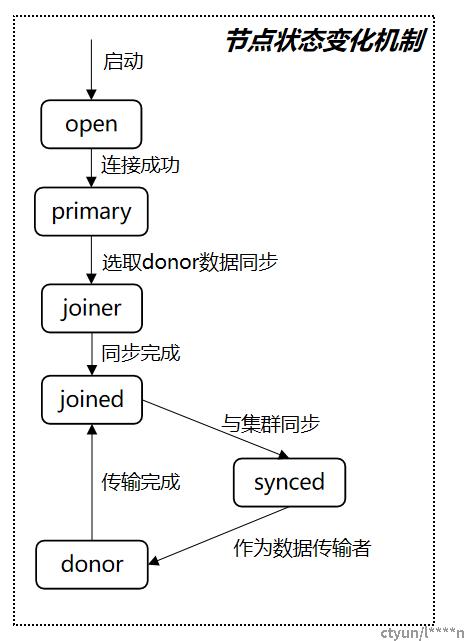
溯源:可用区A中的机器在重启后丢失了到可用区C的网络路由,因此node1只能与node2节点通信。
当node1节点尝试重启时,向node2发起数据同步,node2状态更新为donor,此时集群中只有一个节点node3的状态是synced可用,可用节点个数不足总数的一半,因此集群不可用。
由于node1无法与node3进行通信,因此只有一个节点node2同意其加入集群,不足总数的一半,无法加入集群。node2放弃向node1数据同步,状态更新为synced可用,集群状态恢复为可用。
最终加入路由后,node1节点成功加入集群,解决问题。
