一、混沌工程起源
2008年Netfix决定把它的业务迁移到AWS上,从自身运维的角度考虑,它有很多担忧的地方:
1、很长时间内有两套系统在同时运行,运维的复杂度更高了
2、Netfix的用户量已经达到了1亿,对应用稳定性依赖很高,如果出现故障对用户的影响非常大,甚至是致命的
3、它的业务不断复杂,引入微服务架构,对应用的高可用性要求越来越高
4、生产环境非常复杂,是多样性的,很难在测试环境中完全模拟生产的状态
因此,Netflix决心探索一种在生产环境验证应用高可用性的一种方法,这就是混沌工程
在2012年开源了猴子混沌工具集(github.com/Netflix/chaosmonkey) ,目前start 13.7K 最近更新23年1月,但是国内社区跟进的不多
混沌工程在Netflix的演进发展
- 2010年 Netflix 内部开发了 AWS 云上随机终止 EC2 实例的混沌实验工具: Chaos Monkey
- 2011年 Netflix 了其猴子军团工具集: Simian Army(Java构建),2012年将其开源
- 2014年 Netflix 开始正式公开招聘 Chaos Engineer,提出了故障注入测试(FIT),利用微服务架构的特性,控制混沌实验的爆炸半径
- 2015年 Netflix 和社区正式提出混沌工程的指导思想 – Principles of Chaos Engineering
- 2016年 Netflix前员工Kolton Andrus创立了Gremlin,正式将混沌实验工具商用化,混沌工程影响着越来越多的企业。
- 2017年 Netflix 开源 Chaos Monkey 由 Golang 重构的 2.0 版本,必须集成 CD 工具 Spinnaker 来使用
- 2017年 由Netflix 前混沌工程师撰写的新书“混沌工程”在网上出版
- 2017年 Russell Miles 创立了 ChaosIQ 公司,并开源了 chaostoolkit 混沌实验框架
在这过程,发展了很多混沌注入工具集:
1:Netflix 猴子军团
2:Chaos Monkey: 关闭节点
3:Latency Monkey : 引入延时
4:Conformity Monkey: 关闭不符合最佳实践的实例
5:Doctor Monkey: 查找不健康实例
6:Janitor Monkey: 查找不再需要的资源
7:Security Monkey: 检查系统的安全漏洞
8:i18 Monkey:检查国际化的配置
9:Chaos Gorilla :模拟整个AWS AZ故障
10:Chaos Kong: 模拟整个AWS Region故障
整个发展都是Netflix在生产实践中遇到问题时,利用混沌工程的思想,引入新的猴子(混沌注入工具),实施相应的混沌实践,观察引入故障对系统的影响
二、混沌工程的目的
今天,许多公司,包括国外的 FANG,国内的阿里,华为等,都有自己的混沌工程(Chaos Engineer)
比如阿里在开源的chaosblade :
控制台 chaos-box : github.com/chaosblade-io/chaosblade-box
故障工具集chaosblade: github.com/chaosblade-io/chaosblade
混沌工程的目的:使用某种形式的混沌工程实验,给复杂的分布式系统引入扰动,并观察系统行为,借此发现系统弱点,进而修复该弱点,最总提高系统架构的可靠性.
因此,混沌工程实验中涉及的可行性调研、实验场景和环境的设计与计划、工具的选型和配合方式、系统行为的观测方法、以及找到问题后如何改善系统架构和运维模式,都需要科学的分析和有经验的混沌工程专家指导。
三、chaosbox和chaosblade架构分析
1、chaosbox架构图 chaos-box, chaos-agent,chaosblade 关系
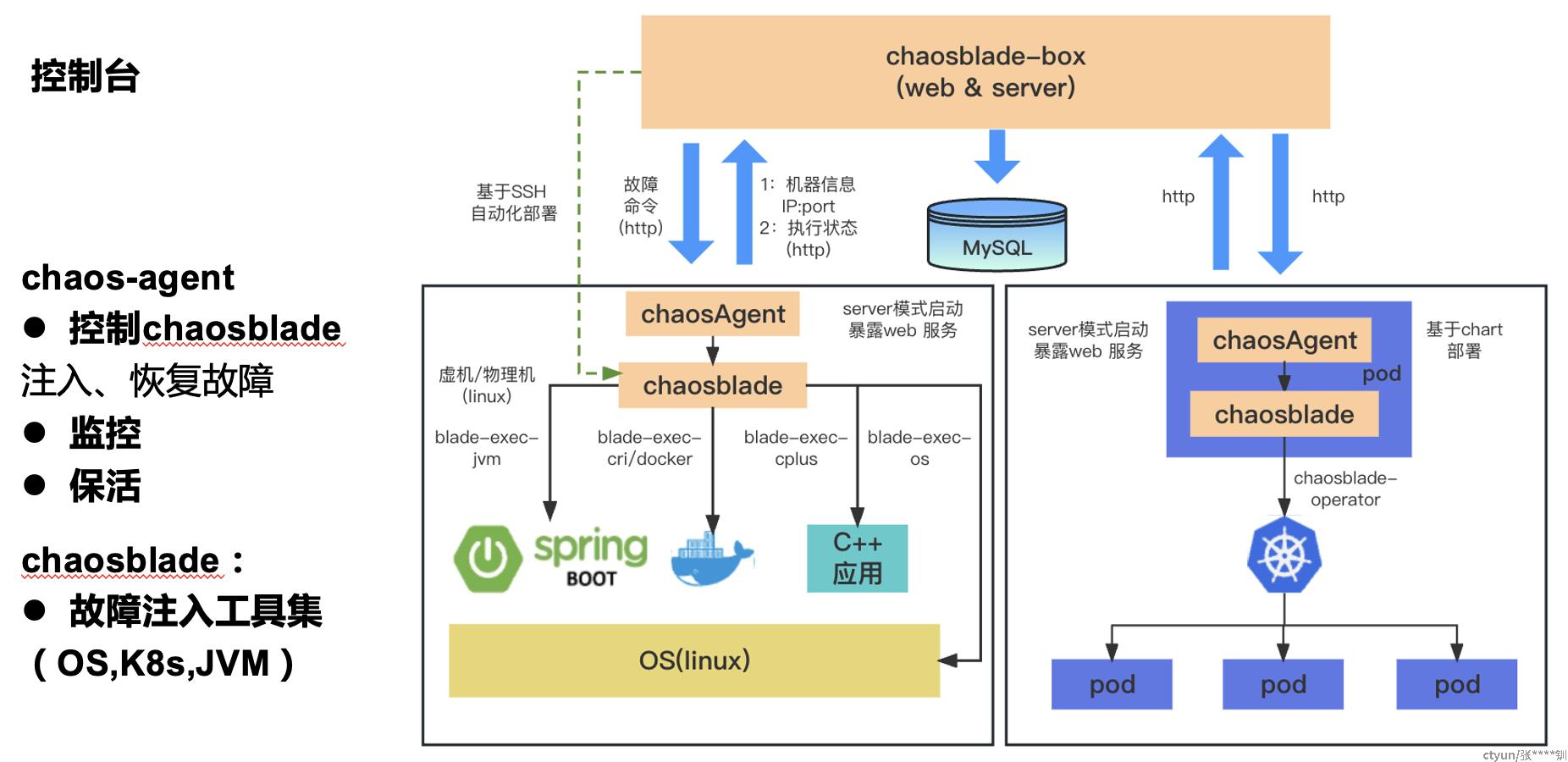
可以看到架构关系: chaosbox控制台主要负责故障命令的编排,通过chaos agent 交互,下发故障注入,恢复命令给chaosblade
其中故障注入工具集为chaosblade,这里重点介绍该故障注入工具集原理
四、chaosblade原理分析
chaosblade 依据领域实现封装成各自独立的项目,每个项目根据各领域的最佳实践来实现,不仅能满足各领域使用习惯,而且还可以通过混沌实验模型来建立与 chaosblade cli 的交互。
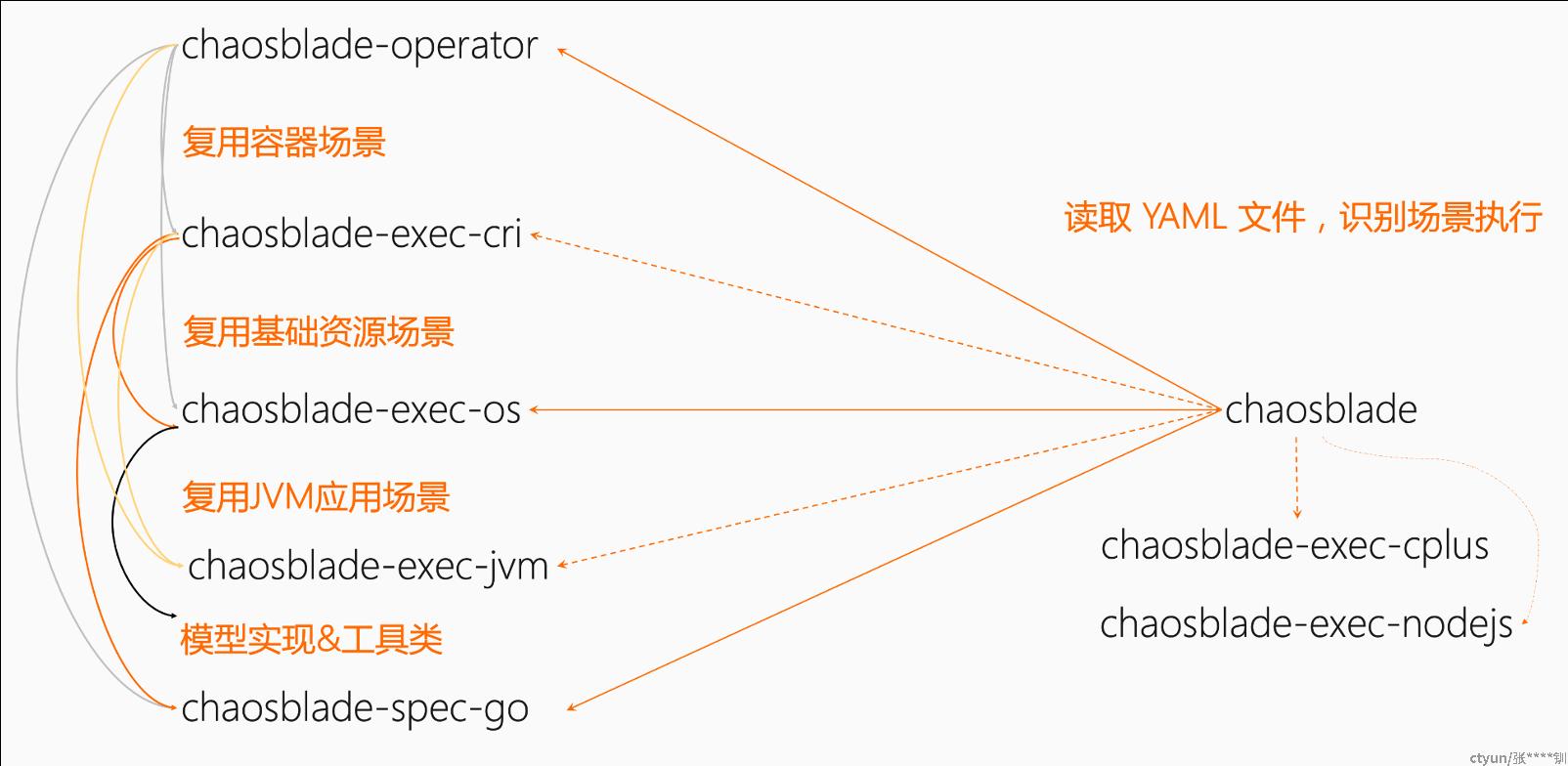
目前社区演进到1.7.2,故障注入支持的场景较为丰富
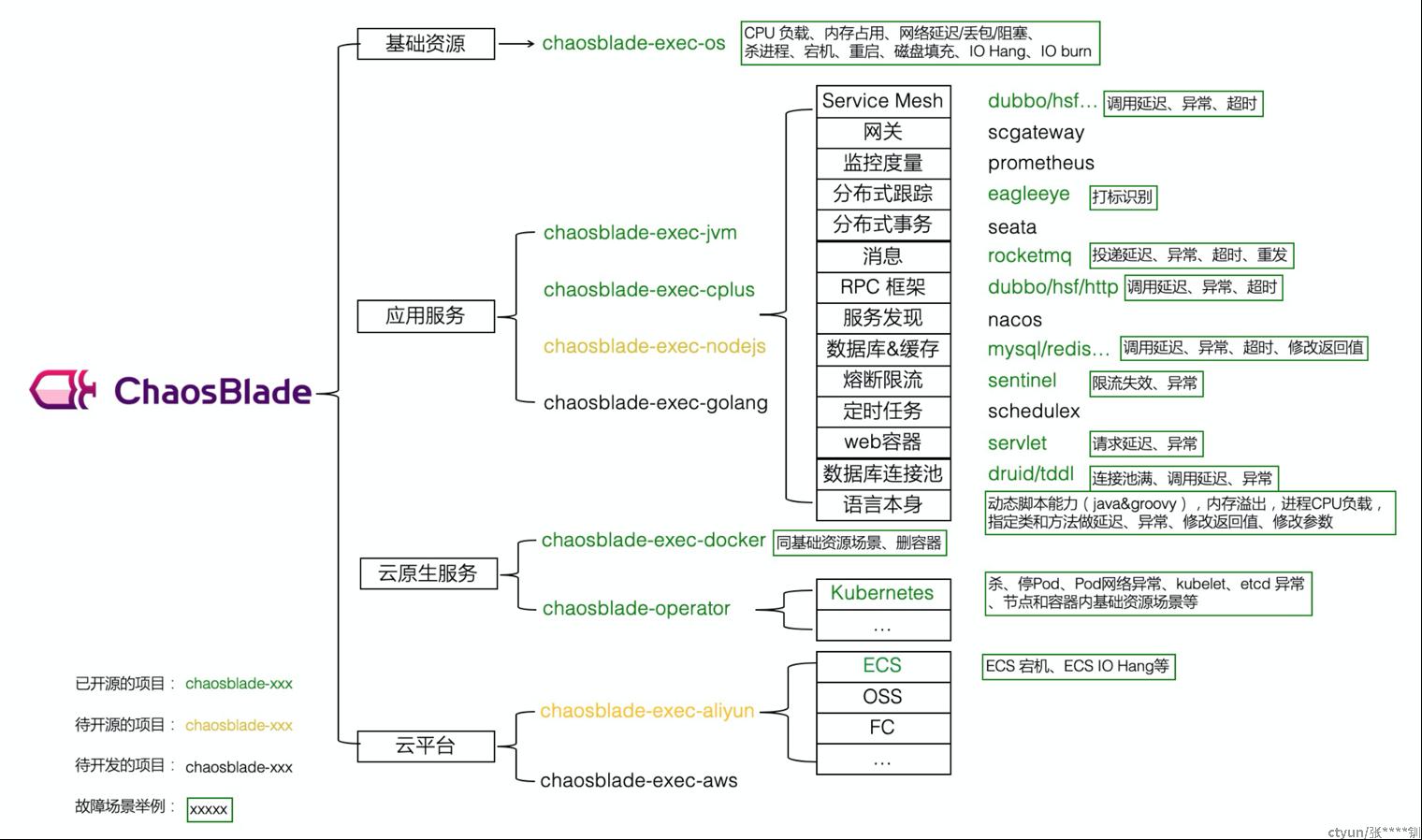
目前开源出来的主要是主机类(linux OS)、JVM类、云原生(k8s)故障注入类别
1 、主机类故障注入原理
基于LinuxOS的基础命令,引发cpu,内存,网络,磁盘,进程资源的变化,基础命令尽量保证基础命令工具是大部分Linux发行版本存在的

主机类故障注入展示
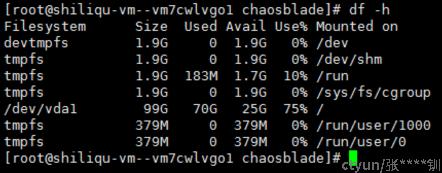
磁盘充填:
blade create disk fill --percent '75' --timeout '905
执行前
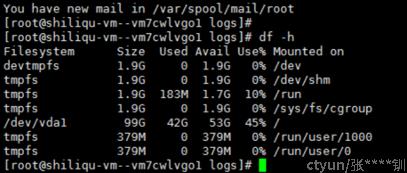
执行后
网络丢包率
blade create network corrupt --percent 80 --destination-ip 198.20.1.81 --interface eth0
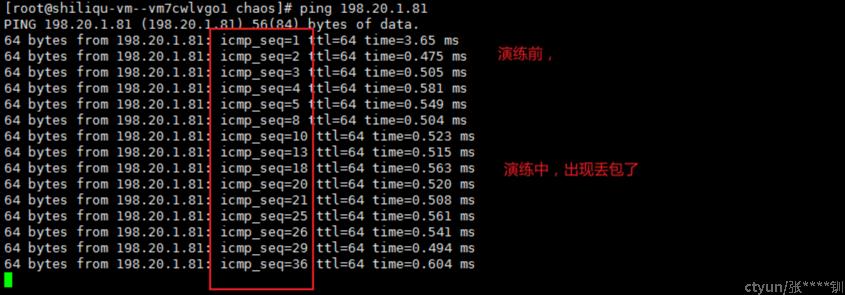
指发往198.20.1.81会出现丢包
2、JVM故障注入原理
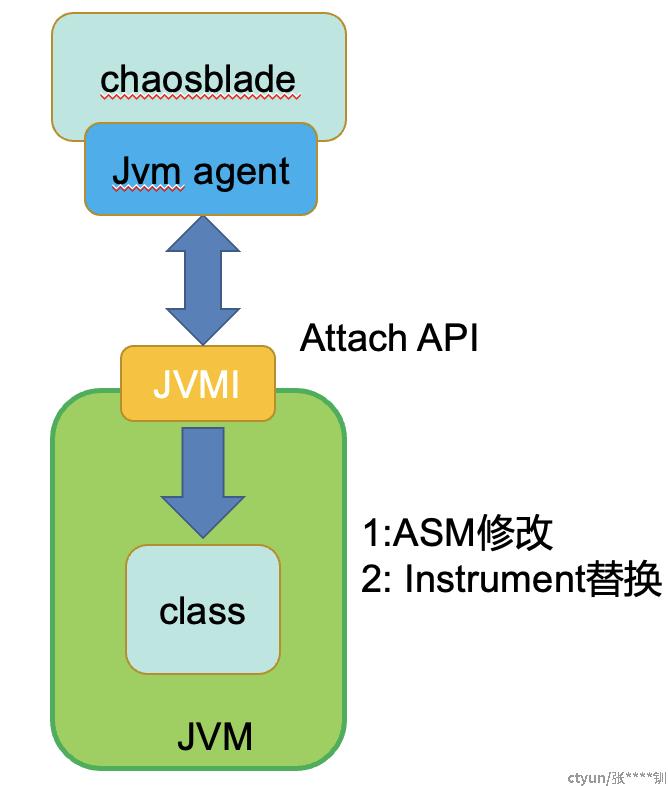
基于JVM agent运行时class重载技术
这是一种运行的JVM类修改并重新加载,一种热加载的技术,基于以下几个JVM技术:
Instrument : JVM提供的一个可以修改已加载类的类库,专门为Java语言编写的插桩服务提供支持,需要依赖JVMTI的Attach API机制实现(JDK 1.6之后可以替换类的字节码)
JVMTI: JVM工具接口,可以对JVM多种操作
Agent: 是JVMTI的一种实现, Agent有两种启动方式: 一是随Java进程启动而启动,
二是运行时载入,通过 attach API,将模块(jar包)动态Attach到指定进程id的Java进程内
Attach API : 提供JVM进程间通信的能力
其中阿里开源的 Arthas(arthas.aliyun.com)在线诊断工具,就是用到该技术
为了更方便大家使用该技术,阿里开源了sandbox,可以方便的编写class 切面和增强代码,
因为有动态挂载过程,这个比较耗时,初次挂载可能需要10秒左右。
比如对jedis的故障注入,那就是要对jedis的实现类进行AOP增强,在before的enhance中加入故障,比如延迟1000ms 就是sleep(1000)
Jedis延迟增加
blade c jvm jedis –time 2000 –process ahas-springcloud-provider –javaHome /usr/lib/jdk1.8.0_201
操作前
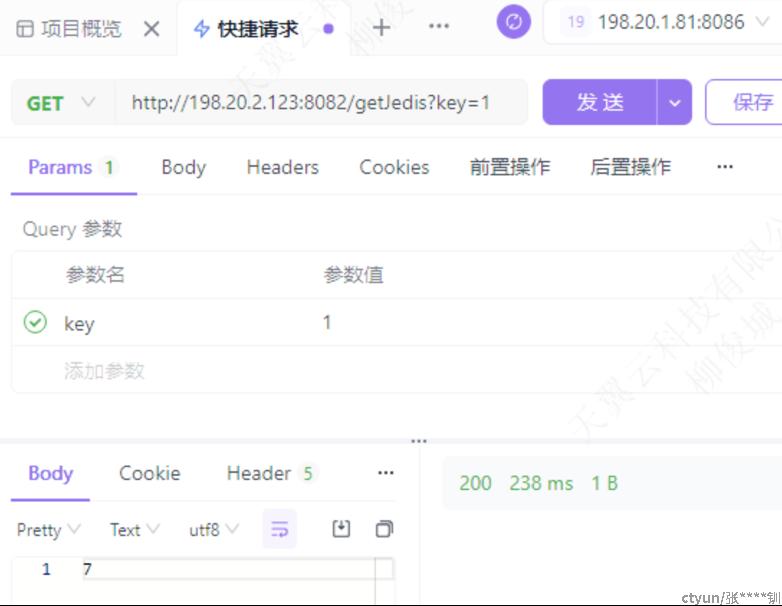
操作后