


Diffusion Model 是一种生成模型,它的工作原理是通过连续添加高斯噪声来破坏训练数据,然后通过反转这个噪声过程,来学习恢复数据³。具体来说,Diffusion Model 分为两个步骤:一个固定的前向扩散过程 q ,逐步向图片增加噪声直到最终得到一张纯噪声;一个学习得到的去噪声过程 p ,训练一个神经网络去逐渐地从一张纯噪声中消除噪声,直到得到一张真正的图片。
在训练后,可以使用 Diffusion Model 将随机采样的噪声传入模型中,通过学习去噪过程来生成数据³。希望这些信息能够帮助您了解 Diffusion Model 的原理。
## 网络结构
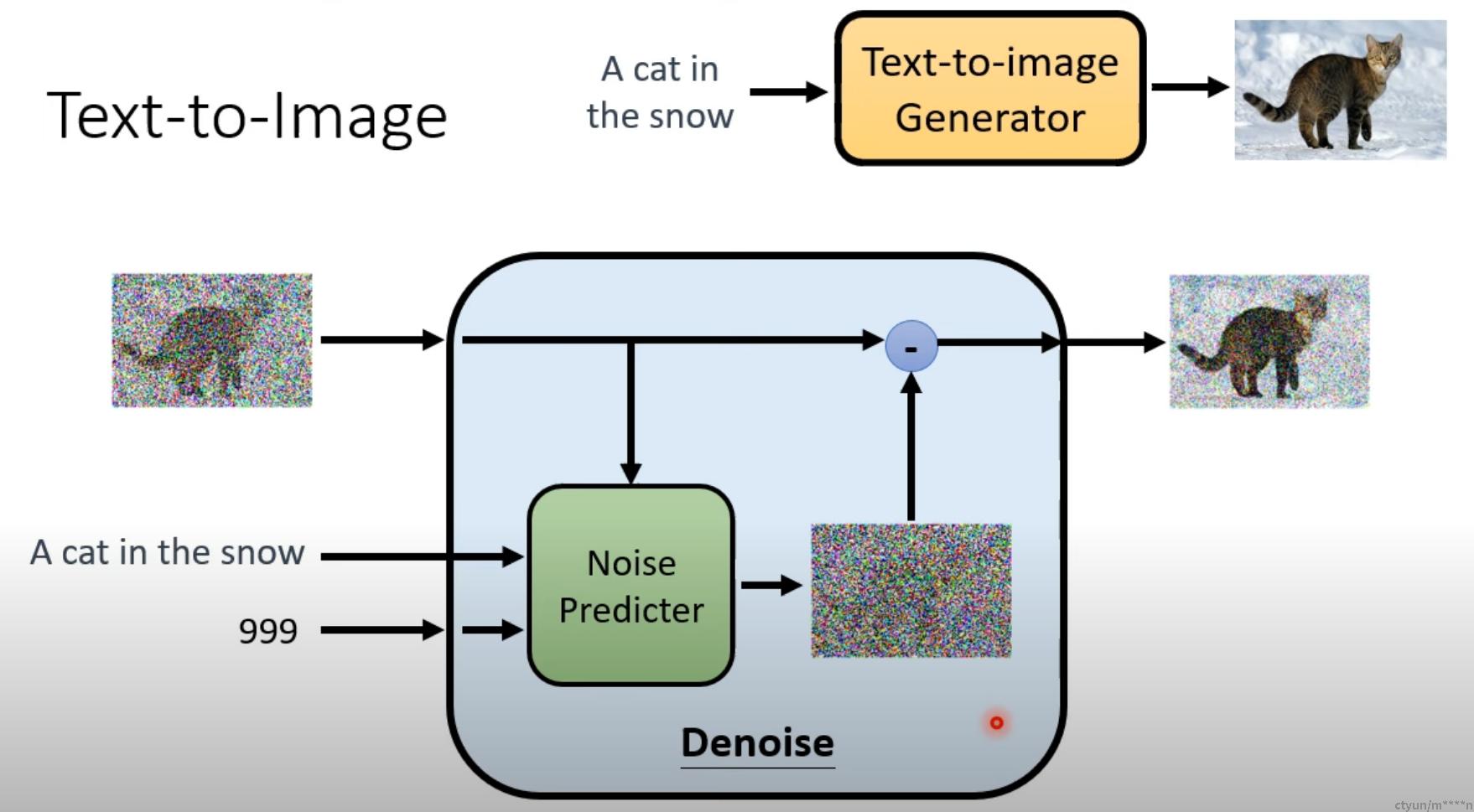
## Noise Prediter训练过程
【输入】: 文字描述、当前step、带有noise的图片
【输出】:noise
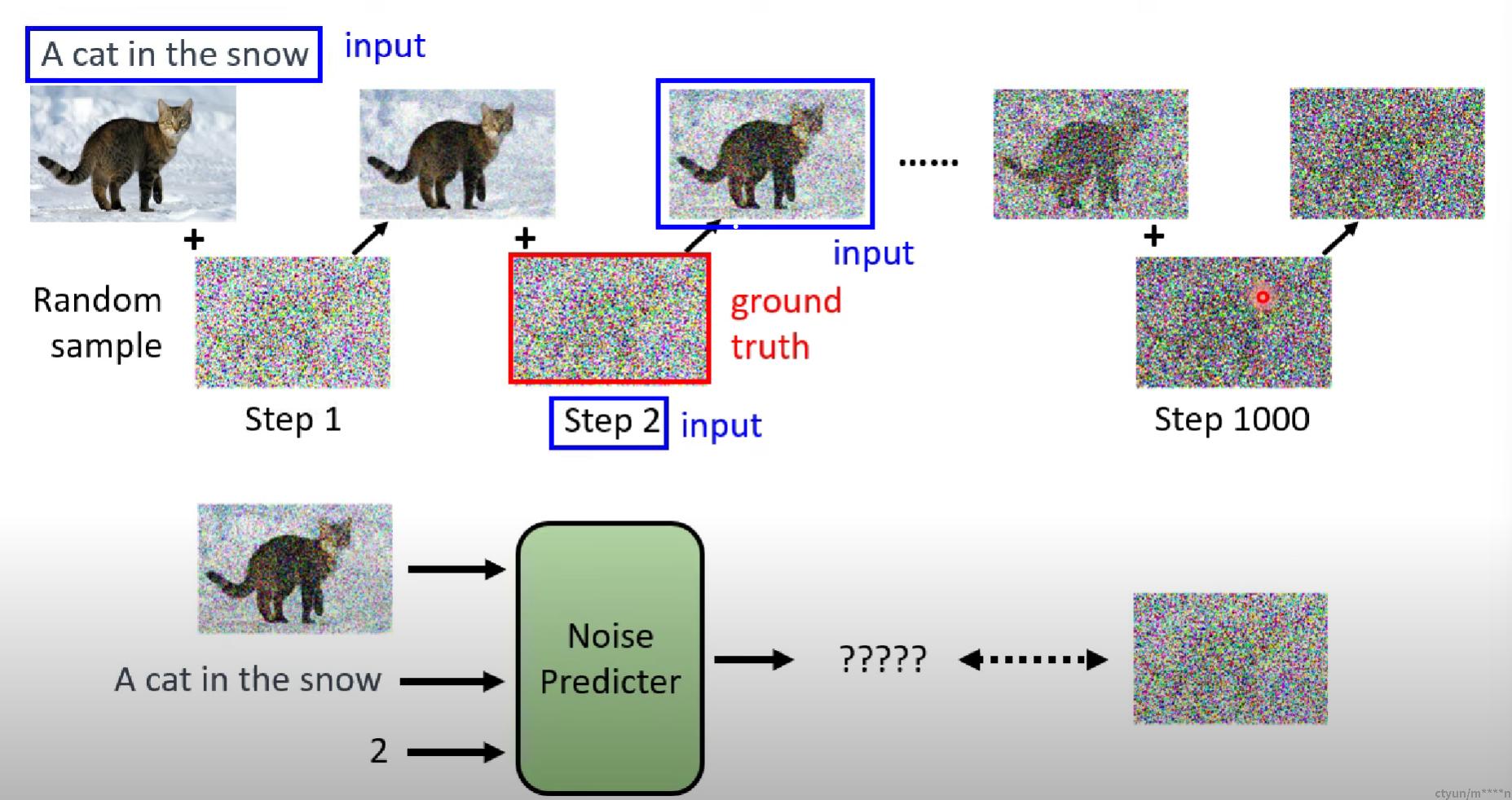
训练数据来源:往正常图片加noise,这样就的得到了训练用到的带有noise的图片,和作为noise prediter输出的noice(groud truth)
## 推理过程
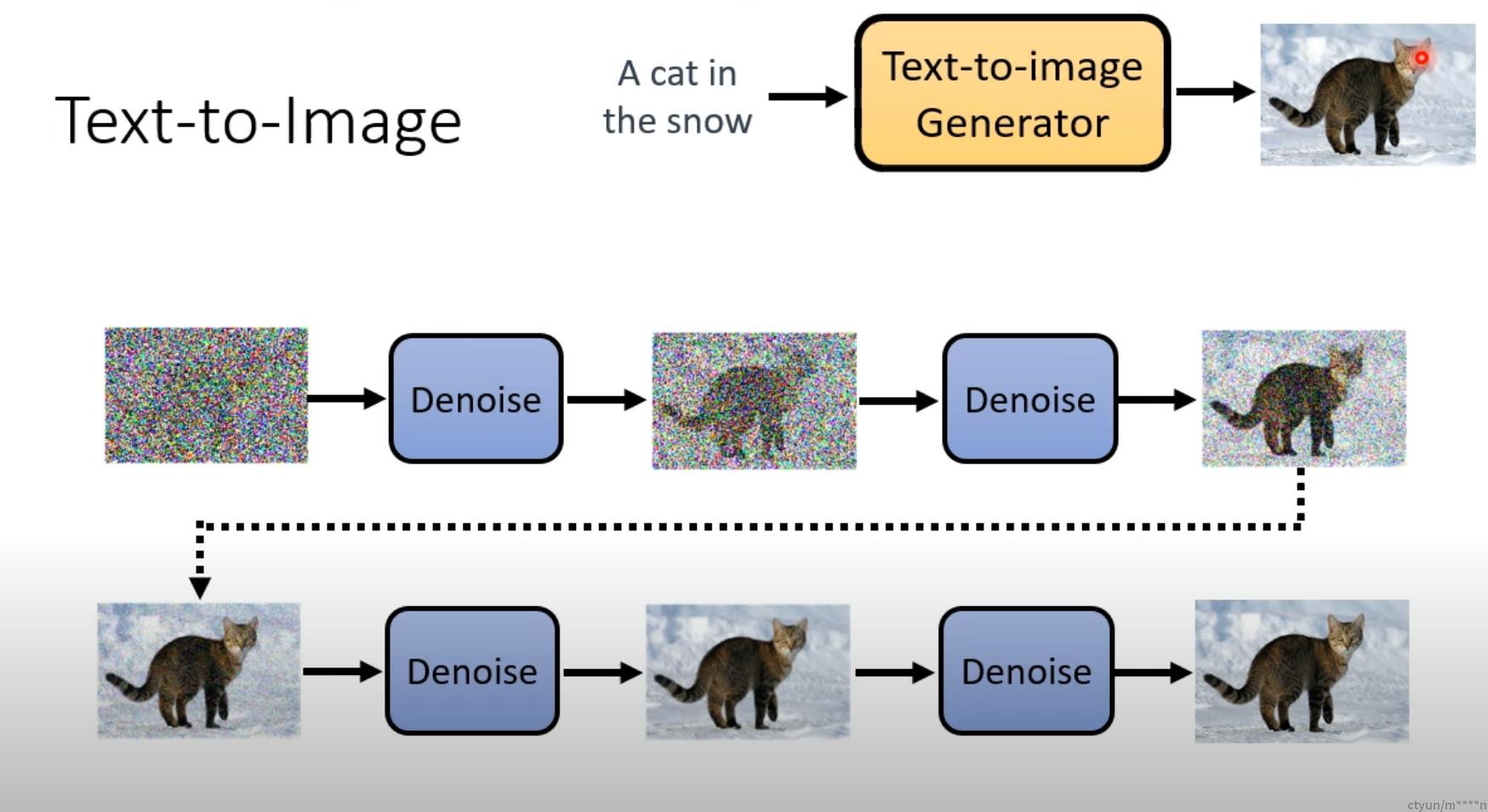
- 输入文字、当前step、带有noise的图片给noise prediter,noise prediter输出noise,然后在带有noise的图片上删除这些noise,输出noise更少的图片
- 重复上述步骤,直到输出完美的图片
米开朗琪罗曾说雕塑本来就存在于材料里面,自己只不过是把多余的东西去除了。Diffusion Model有异曲同工之妙。
## 总结
直接训练得到一个text2image model是很困难的事情,而识别noise是一个更简单的任务,通过多次执行去noise步骤实现图片的生成,对机器来说只需要学习noise detection,将复杂的问题转化为更简单的问题。
