



一、前提
本文基于 v1.80.0 版本的源码分析,可从github上下载cluster版本对比分析代码:https://github.com/VictoriaMetrics/VictoriaMetrics。后续版本变化理论上不会很大。
二、整体架构
开源版本分为single-server(一个包运行所有模块)的单节点模式和cluster模式,单点模式合适本地测试使用,生产使用的cluster模式分为vmselect、vminsert、vmstorage三个主要模块:
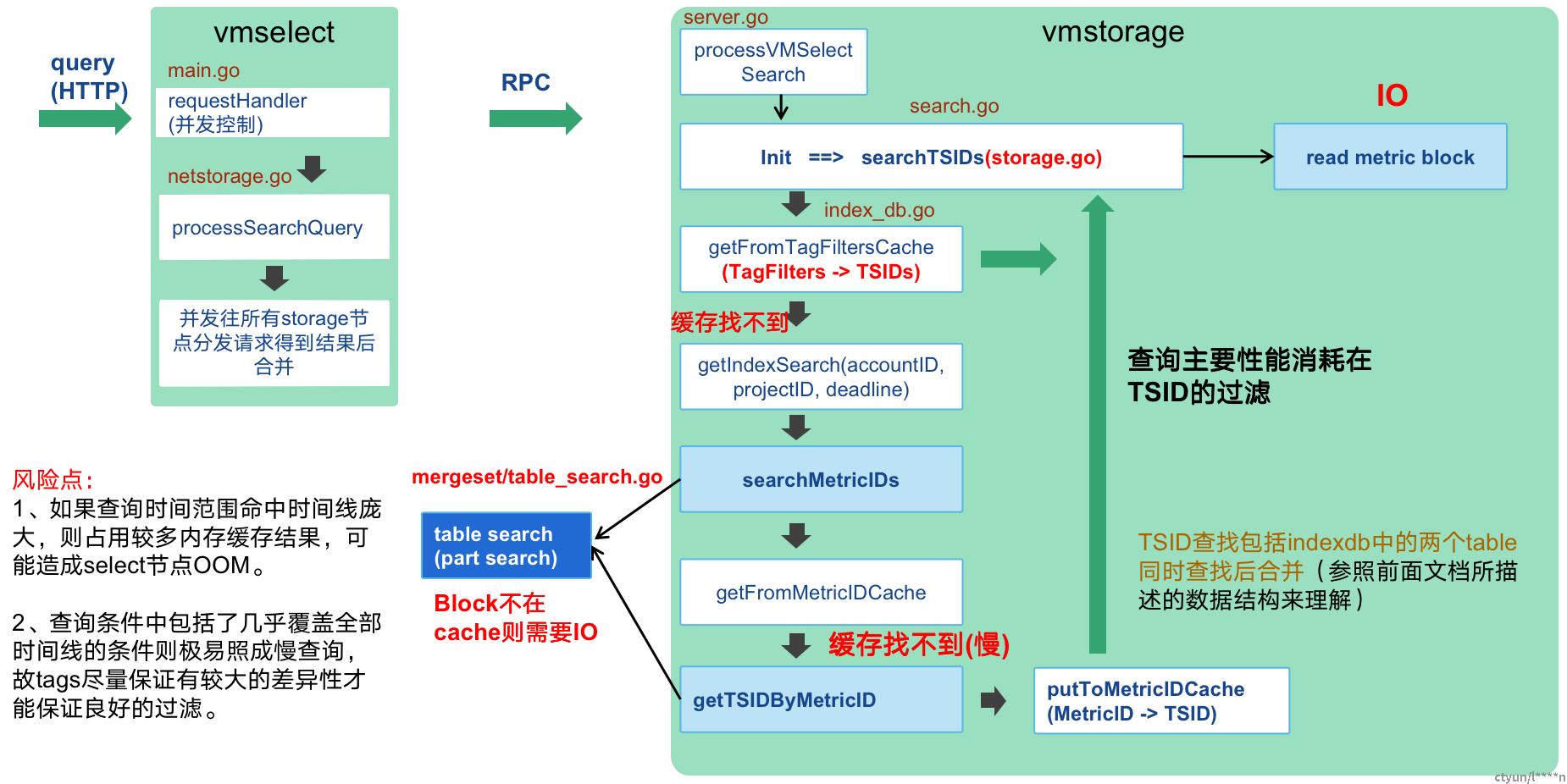
(1)vmselect:查询模块,可无状态部署,客户端发送请求到查询模块后,查询模块会把请求分发到所有storage模块(由于没有元数据中心节点,固数据存储在哪无法感知,类似clickhouse的设计模式),得到原始的block数据后在select模块进行合并,再得到一个总结果。
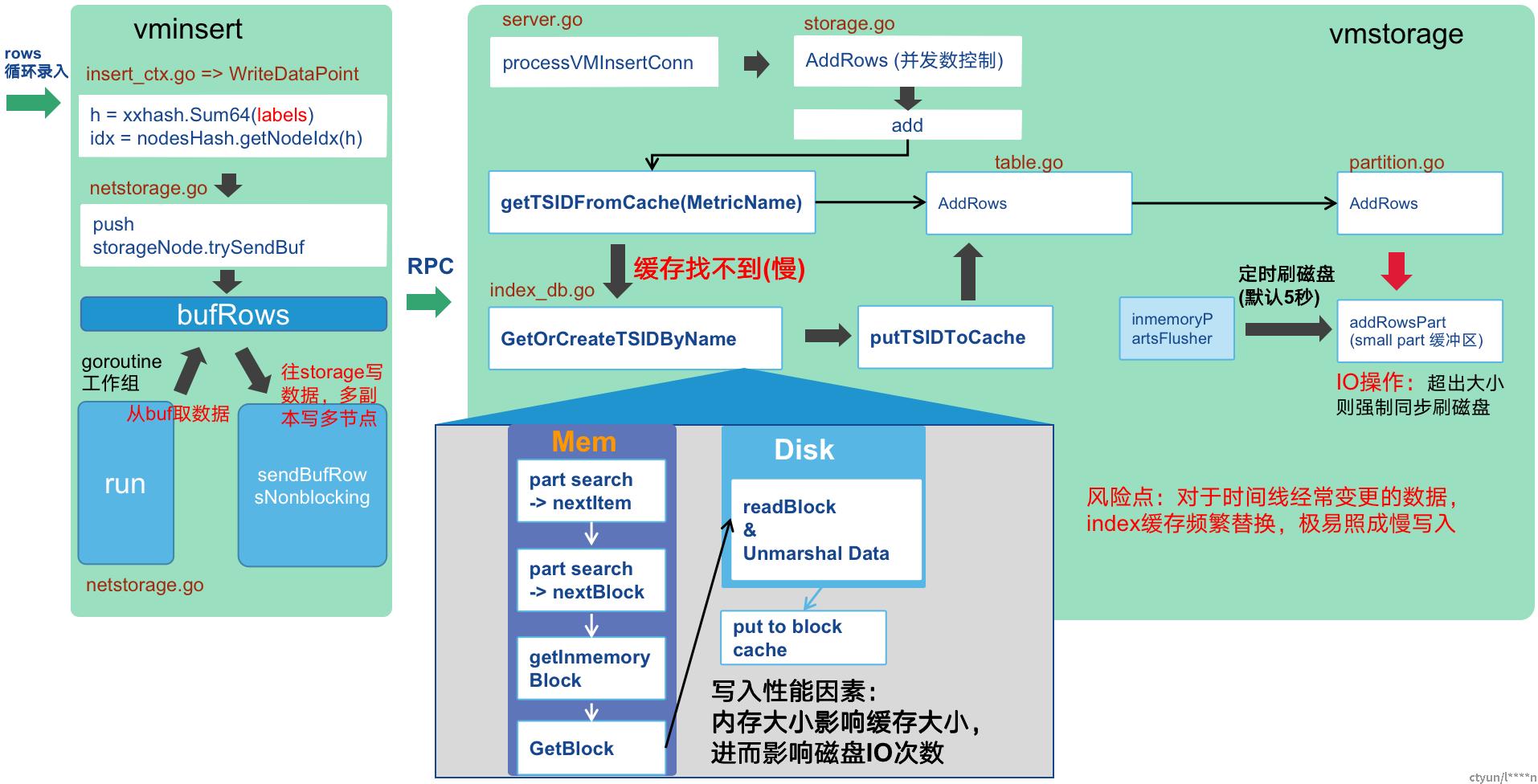
(2)vminsert:写入模块,可无状态部署,写入数据的请求发到此模块后,根据labels通过一定的hash计算出一个值,根据这个值确定此条数据发往哪个storage节点。因此相同的时间线会往同一个点节点发送,如果有某个时间线数据量特别大则会出现数据倾斜问题后某个storage写入和查询压力都会增大。在扩容货缩容后,由于节点的列表变更,固计算出的hash发往的storage节点也会变更。
(3)vmstorage:存储模块,有状态,存储模块的移除须先从select和insert的配置中移除才不会有异常,此模块压力最大,非常消耗内存和IO,固推荐使用SSD和比较大的内存,宁愿用大规格的机器也不用量多但规格较小的机器(缓存不命中则会造成较多的IO,性能下降严重)。
三、vmstorage 存储模块
存储模块最为复杂,也是整个vm的重点,select模块更多偏向于数据调度和汇总,insert模块也是控制数据写入分发。本文重点讲难度最高的 storage 模块,也只是属于个人理解。
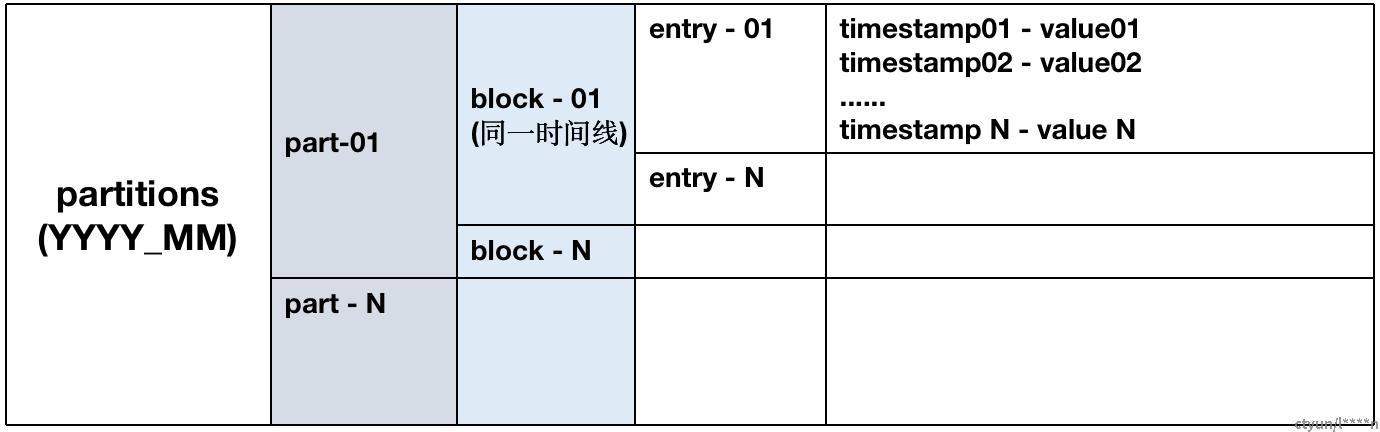
1、存储目录结构

/data 数据目录的逻辑结构如下:
(1)每个block只包括一个时间线,内部根据时间排序。
(2) 每个block最大容纳8000个sample,不同block可并发处理。
2、 写入流程与风险点
四、查询流程与风险点
查询模块将请求发往各个vmstorage节点,并汇总各个节点的数据,负载最大也在vmstorage节点:
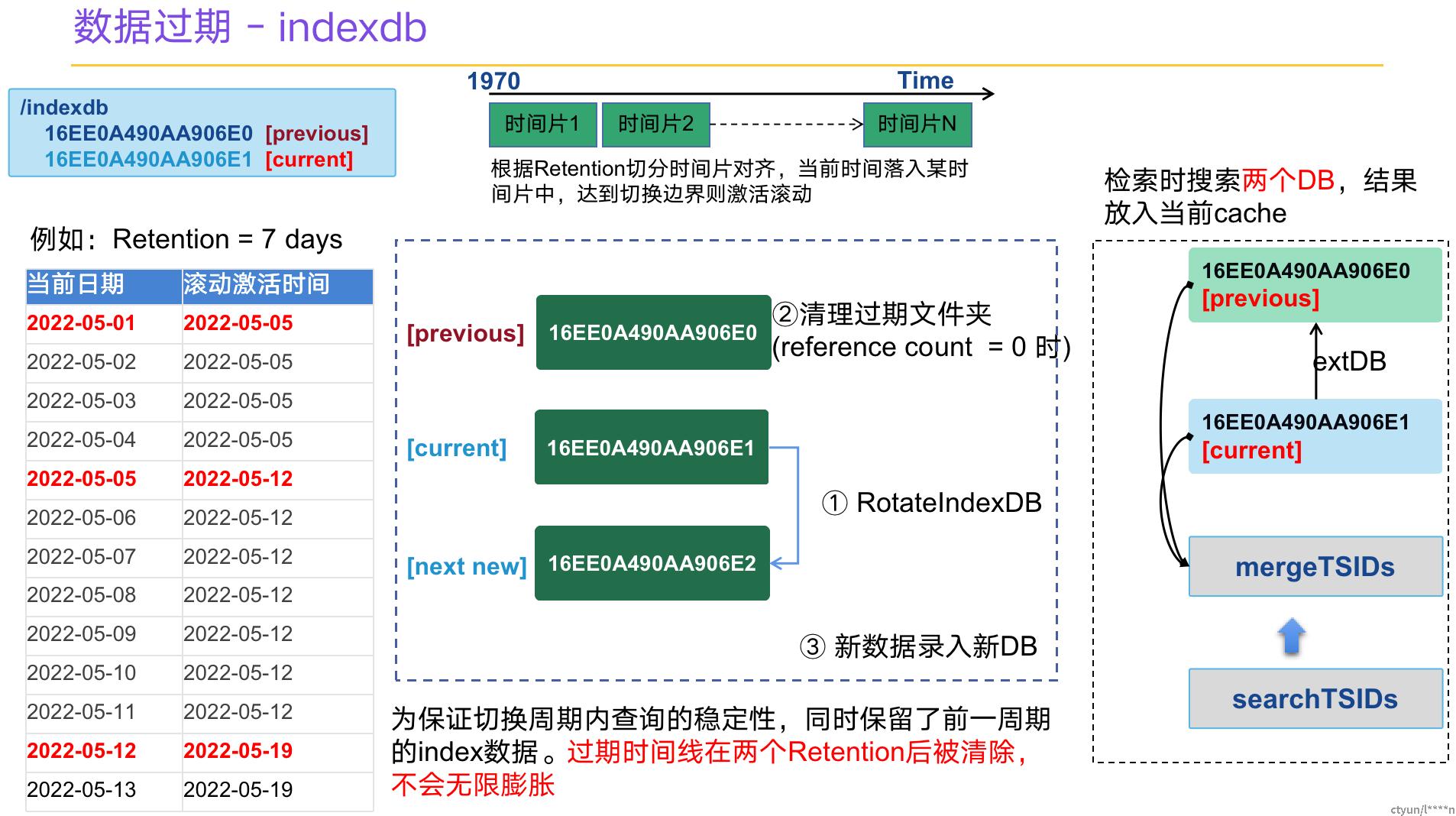
五、数据过期规则说明
VictoriaMetrics 开源版本的数据过期有个缺陷,只支持集群级别的过期,企业收费版本才支持租户级别的过期,故这一点对有这类需求的用户也会照成困扰。下面仅针对开源版的过期机制进行讲解:

六、数据安全性保障与运维能力总结
(1)VictoriaMetrics 并未使用WAL,而是直接写入类似SSTable的内存结构中,定时刷写磁盘,这是此模块能表现出极高的写入性能的一个原因,如果是单副本则宕机时有可能照成最近的少量数据丢失,如果是数据安全性要求极高的场景,则建议开启双副本模式。
(2)双副本状态下,写入性能有一定的下降。即使在双副本模式下,不能同时下线两台主机,如果同时下掉两台主机则数据会丢失,为保证数据安全,建议对存储层配置RAID1、RAID5或RAID10保证数据安全性,迁移时将数据从data目录直接迁移走即可在另一主机运行。
(3)vm配置有grafana的监控模板,安装即可观测各个模块的性能,需要结合代码才能比较深入的了解各个指标的作用含义。
总之,这款用go编写的开源TSDB性能表现很好,要能驾驭这组件需要比较多的功力,如果数据量很大则需要了解原理才能把控得住它,数据量很小则很容易处理,不担心性能问题。
