


1、指定某个set不切换
方法:通过调用keeper的bin目录下的excluded_set工具来执行
例子:设置集群set_9697988001不切换
./excluded_set -i "set_96978801"
注意:该工具是覆盖性添加,例如原来已经设置了集群A不切换,同时想设置集群B不切换,则应该./excluded_set -i "A,B",后续如果想取消对集群B的不切换仍保留集群A的不切换,则应当执行./excluded_set -i "A"
2、手动触发主从切换
方法:通过调用keeper的bin目录下的mansw工具来触发主从切换,使用方式如下:
例子:设置集群set_9697988001发起主从切换
A、切换到指定的从库:
将主从10.142.90.96_8001切换到10.142.90.97_8001,命令如下:
./mansw test set_9697988001 10.142.90.96_8001 10.142.90.97_8001
B、自动切换到复制最快的从库
./mansw test set_9697988001 10.142.90.96_8001
3、重建主从关系
场景:有时候主从关系混乱,需要重做主从关系(注意:这里没有对集群实例进行备份恢复操作,若主从数据不一致,需要先重做从库),重建主从关系步骤如下:
A、删除原set集群主从关系。调用keeper的bin目录下面的工具:./delset set_9697988001
B、清除主从上集群的复制信息,主从上都执行:reset master;stop slave;reset slave;reset slave all;
C、利用keeper的bin目录下面的noshard_create_set来重建set
注意:有场景由于切换失败,在不影响应用的场景下需要重建主从,可以通过手动直接更改对应set的setrun信息来重建主从关系:
原zk信息
[zk: 127.0.0.1:16001(CONNECTED) 8] get /beta0.1/sets/set@set_0708096608/setrun@set_0708096608
{"master":{"alive":"-1","city":"default","election":true,"idc":"default","losthbtime":"1449229074","name":"134.130.131.8_6608","weight":"1","zone":"default"},"password":"","set":"set_0708096608","slave":[{"alive":"-1","city":"default","election":true,"idc":"default","losthbtime":"1449229062","name":"134.130.131.7_6608","weight":"1","zone":"default"},{"alive":"-1","city":"default","election":true,"idc":"default","losthbtime":"1449229014","name":"134.130.131.9_6608","weight":"1","zone":"default"}],"specid":45319304,"status":0,"user":""}
直接修改zk节点信息:
set /beta0.1/sets/set@set_0708096608/setrun@set_0708096608 {"master":{"alive":"0","city":"default","election":true,"idc":"default","losthbtime":"1449229074","name":"134.130.131.7_6608","weight":"1","zone":"default"},"password":"","set":"set_0708096608","slave":[{"alive":"0","city":"default","election":true,"idc":"default","losthbtime":"1449229062","name":"134.130.131.8_6608","weight":"1","zone":"default"},{"alive":"0","city":"default","election":true,"idc":"default","losthbtime":"1449229014","name":"134.130.131.9_6608","weight":"1","zone":"default"}],"specid":45319304,"status":0,"user":""}
4、终止正在切换的主从任务
场景:在集群发生故障时,由于各种原因切换失败或者长时间超时等待,为了不影响应用,需要尽快恢复服务,可以终止该切换任务,保证主库存活,不影响应用
A、停掉所有的keeper进程
B、去zookeeper上删掉相关的切换任务;
[zk: localhost:2181(CONNECTED) 0] get /teledb/jobs/consfailovers/consfailover@set_7273746606
{"Last_Stat":"10.145.190.72_6606|10.145.190.73_6606|10.145.190.74_6606","Start_Time":"1464926095498","errorcode":"0","errorinfo":"ok","gjid":"GJID_CONSIST_FAILOVER_0000000077","reason":"failover","server_id":"190726606","set":"set_7273746606","slaves":[{"Gtid_IO_Pos":"","Master_Host_Port":"","host":"10.145.190.73_6606","is_maxrelaylog":"0","log_file":"binglog.000000","log_file_pos":"0","status":"undo"},{"Gtid_IO_Pos":"","Master_Host_Port":"","host":"10.145.190.74_6606","is_maxrelaylog":"0","log_file":"binglog.000000","log_file_pos":"0","status":"undo"}],"srchost":"10.145.190.72_6606","step":"degrade"}
[zk: localhost:2181(CONNECTED) 1] rmr /teledb/jobs/consfailovers/consfailover@set_7273746606
[zk: localhost:2181(CONNECTED) 0] get /teledb/monitors/monitor@GJID_CONSIST_FAILOVER_0000000077
{"deal_event_desc":"consfailover job timeout","deal_evnet":"100000","deal_path":"/teledb/jobs/consfailovers/consfailover@set_7273746606","desc":"","gjid":"GJID_CONSIST_FAILOVER_0000000077","starttime":"1464926095","timeout":"1464929095"}
[zk: localhost:2181(CONNECTED) 1] rmr /teledb/monitors/monitor@GJID_CONSIST_FAILOVER_0000000077
5、将集群从半同步状态更改为异步状态
场景:teledb中的半同步(一致性容灾)集群在变成单主后,变成只读,应用无法写入,此时如果想让单主可写,可将集群类型修改为异步(非一致性容灾)
1、修改set对应的setrun节点
[zk: localhost:10001(CONNECTED) 0] get /teledb/v2.7/140/sets/set@set_96978803/setrun@set_96978803
{"failovertype":0,"master":{"alive":"0","city":"default","election":true,"idc":"default","losthbtime":"0","name":"10.142.90.96_8803","weight":"1","zone":"default"},"password":"","set":"set_96978803","slave":[{"alive":"0","city":"default","election":true,"idc":"default","losthbtime":"0","name":"10.142.90.97_8803","weight":"1","zone":"default"}],"specid":0,"status":39624266,"user":""}
2、将对应节点内容的failovertype属性值改为1
注意:后面如果需要将集群从异步状态改为半同步状态,除了需要将该zk节点值改为0,还需要在主库上执行如下语句:set global rpl_semi_sync_master_enabled=1
6、利用agent的alldump功能重做两个从库
场景:从库因为各种与主库不一致,相差事务太多,无法通过手动执行相差的gtid事务来修复,除了可以利用备份恢复的功能来恢复该从库,还可以利用agent的alldump功能来重做该从库(实质上也是备份恢复,只是agent实现了相应功能),操作步骤:
A、确保机器上都安装了xtrabackup备份工具;
B、进入从库机器的数据库目录执行下列命令:
rm -rf binlog data logs relaylog tmp xtrabackuptmp;
mkdir -p binlog data logs relaylog tmp xtrabackuptmp
C、kill掉相关数据库进程,等待触发alldump功能,恢复从库(alldump的日志可以去agent的bin目录下进行查看)
7、主从切换失败场景及修复方法总结
Agent周期性检查数据库的状态,判断可连接、可读、可写的情况,并把心跳信息写到zookeeper的节点。
Keeper检查心跳信息,根据保活策略(alivepolicy)判断心跳是否正常,alivepolicy参数设置如下:
scheduler增加保活策略(alivepolicy),设置zk节点/teledb/configs/cfg@recovery即可修改相应策略,alivepolicy可取值:
0(默认)、忽略连接的1040错误,连接、读、写的2013错误;
具体说来
忽略连接错误中的“connect error[Too many connections], errno:1040”和“connect error[Lost connection to MySQL server at 'waiting for initial communication packet', system error: 110], errno:2013”,
忽略可读错误中的“query error[gone away agin], errno:2013,sql[select count(0) from SysDB.StatusTable limit 1]”,
忽略可写错误中的“query error[gone away agin], errno:2013,sql[select count(1) cnt from INFORMATION_SCHEMA.PROCESSLIST where info like 'replace into SysDB.StatusTable set ts = from_unixtime”;
1、连接、查询、更新任意错误皆是失败心跳;
2、忽略连接、查询错误,仅更新有错误是失败心跳。
当心跳成功时,SCHEDULER会把LastlosthbTime设为0
当心跳失败时,会把LastlosthbTime设为当前的时间,同时把资源目录里的alive值设为-1(备库的ALIVE为-1时,即使发生了切换也没有成为主库的资格了)。当主库丢失心跳时间超过设置的maxlosthbtime,就会发起容灾切换任务,切换过程如下:
1、KEEPER下发CONSFAILOVER切换任务
2、主AGENT 执行DEGRADE SWJOB
3、从AGENT执行REPORT RELAY SWJOB
4、KEEPER收到两个从库的REPORT结果,挑选切换主库
5、被挑中的从库执行RELAY LOG APPLY SWJOB
6、KEEPER收到APPLY 成功,设置SETRUN
7、AGENT执行重建主从
以上在切换步骤中,可能失败的典型场景及处理措施
场景1:设置了不切换集
失败典型场景,该SET设置了不切换。
Telemonitor显示如下:
检查zookeeper ~ /configs/cfg@recover excluded_sets内容是否包括指定的set。也可以搜索Keeper日志,关键字ignore the set,确认是否有忽略set。可以使用excluded_set工具,设置与关闭不切换set。
场景1成功相关日志:
consfailoverjob gen a new GJID:
success deliver a consfailoverjob
步骤2:relaylog不断增长
失败场景:直连主库数据库,持续进行DML语句,主库agent宕机导致主从切换,在REPORT RELAY LOG阶段,agent检测到relay log仍在不断增长。会一直等待。这样导致整个切换过程完成不了。
解决方法:断掉直连主库的连接,
场景3:maxdelay阈值过小
失败场景:MAXDELAY阈值设置过小,或者切换过程持续时间较长,这个是最常出现的失败场景,实际上可以设置一个较大的MAXDELAY。
此步骤失败,在keeper日志中找到如下的报错关键字信息:
[2021-03-24 09:38:17 586860] INFO 1991,func_consfailover.cpp:342:GetRelaylogFilePosAns,tid:0x7fdbc5808700,host 132.121.218.92_8112 set set_9288878112 delay 730 larger than maxdelay 300
[2021-03-24 09:38:17 586864] ERROR 1991,func_consfailover.cpp:360:GetRelaylogFilePosAns,tid:0x7fdbc5808700,there is no valid slave host for replace master
telemonitor显示如下
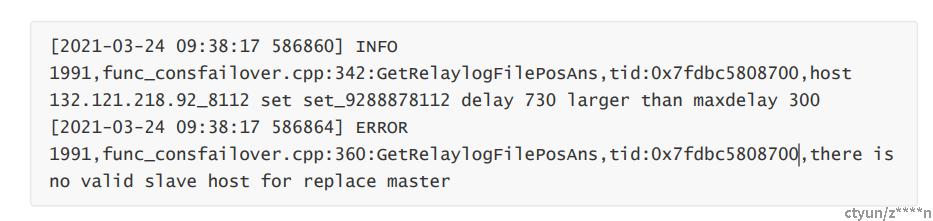
解决方法1:
检查两个从库的GTID情况,在GTID较大的从库执行
update sysdb.statustable set ts=now() where ip='master_ip' and port=master_port;
解决方法2:
还可以增大zk上的/teledb/configs/cfg@recovery中的maxdelay值来使延时落在该范围内;
场景4:从库apply relaylog失败
失败场景:备选主库的SLAVE SQL无法启动,或者出现复制错误(DUPLICATE KEY等)。最常出现的SQL线程复制出错导致整个切换过程失败。
在从库执行Show slave status\G 查看Last_SQL_Errno信息,并根据不同的错误类型决定解决办法。如果出错的事务可以忽略,可以在从库执行以下操作跳过这个事务;如果出现重复主键,可以删除重复的主键行;或者数据一致性已经损坏,只能通过备份恢复重建主从。
set @@sql_log_bin=0;
set gtid_next='要跳过的GTID';
begin;
commit;
set gtid_next=AUTOMATIC;
场景5:从库闪回失败
此时,对keeper来说容灾切换的过程已经完成,但是在重建主从的过程中,有以下失败场景:选出的新主库多的 GTID对应的binlog已经删掉,这时不能自动重建主从;从库有多余的GTID需要闪回,但是对应的binlog已经被删除了。以上两个情况,都不能自动重建主从,而且这种失败场景不宜发现。在Telemonitor主从切换过程是正常的,但是集群详情,会发现主从状态异常,从库延迟持续变大。这时,只能通过拉取全量数据恢复集群。
拉取全量数据可以手动备份恢复,或者利用agent的自动备份恢复功能。利用agent的自动备份恢复功能操作如下:
重命名数据目录并建立一个空文件夹。
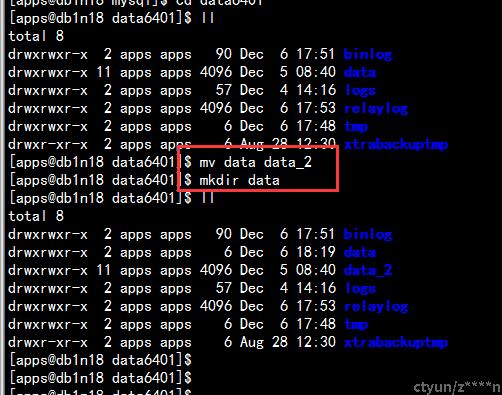
之后观察xtrabackuptmp目录或者查看xbstream进程确认正在执行自动拉取全量数据。
针对这种失败场景,首先,严禁连接从库执行DML语句,做好权限管理;其次telemontior也有监控,如果有直连从库执行事务,telemontior会检测到GTID的变化给出告警,对这类告警信息要特别注意、提高警惕。不要等到最后binlog已经被删除,切换失败了再去处理。
8、主从切换详细流程介绍
场景:在TeleDB组件推广实际应用中,各省同时遇到切换相关问题,不知所措,对切换流程不熟悉,对此,特整理了一份切换流程的详细过程;
切换流程如下:
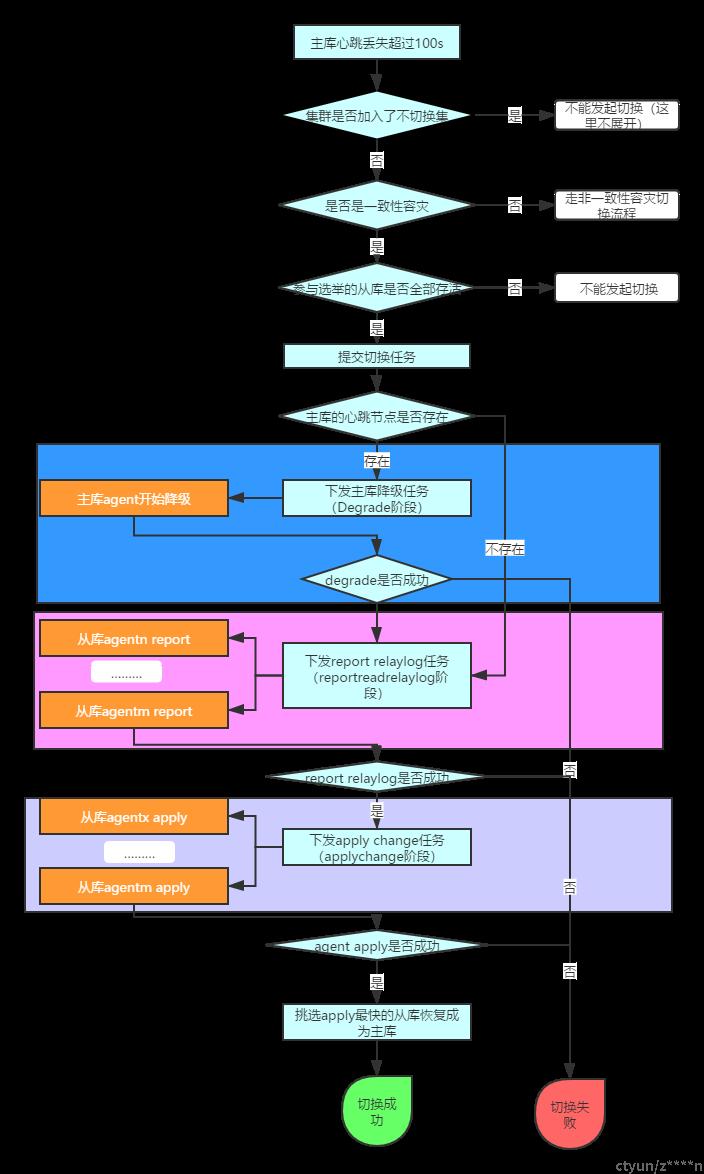
详细流程介绍:
A、keeper发起切换
1、keeper每5秒(配置文件设置)去检测主库agent的心跳,如果发现心跳丢失时间丢失100s(配置文件中标红设置),则说明可能需要发起切换;
日志关键字:
heartbeat lost execeed MaxLossHBTime, crash down!!
2、判断改集群是否加入了不切换集。主要是获取zk上的./configs/cfg@recovery节点中excluded_sets属性值是否包含了该set,如果包含,则忽略此次主库异常,直接退出
3、判断该对应set的setrun属性中的failovertype属性值是否为0,是的话进入一致性容灾处理逻辑(非一致性容灾处理此处不做详细介绍)
4、判断针对该集群keeper是否已经发起了切换任务,如果已经对该set发起了切换,则忽略此次检测:
日志关键子:
already exists and could not create again
5、判断是否有合适的从库,即参与选举的从库是否全部存活,如果不是,则直接出错退出
日志关键字:
is not alive and can not start a failover process
如果没有可参与的从库也直接出错退出
日志关键字:
no usable slave for set
如果setrun中有tmp host,也会出错退出
日志关键字:
has reptmp host and can't start a failover process
6、提交切换任务至zk,切换任务内容大致如下:
success deliver a consfailover job. gjid: GJID_CONSIST_FAILOVER_0000000352(提交切换任务的开始打印内容)
set znode /sz_cbs_teledb/jobs/consfailovers/consfailover@set_9288878112 {"Last_Stat":"132.121.214.88_8112|132.121.214.87_8112|132.121.218.92_8112","Master_Lost_Time":"1616551664","Start_Time":"1616552906517","errorcode":"0","errorinfo":"ok","gjid":"GJID_CONSIST_FAILOVER_0000000352","reason":"failover","server_id":"214888112","set":"set_9288878112","srchost":"132.121.214.88_8112","step":"submit"}
keeper 判断是否需要Degrade
1、提交的切换被keeper watch到,keeper经过下列判断后进入是否进入degrade阶段,主要判断主要有如下几个方面
a、如果zk上对应set的setrun节点不存在,则直接报错提出
关键日志 get setrun %s failed [%d], %s
b、如果setrun中的master host和切换任务中的srchost不匹配,则也报错退出
关键日志 master host %s is not the master of set %s which master is %s
c、如果主库存活(心跳正常),且切换原因不为manaul的话,则也报错退出
关键日志 set %s master %s is ok
d、如果setrun中的tmphost不为空的话,则也报错退出
关键日志 set %s has reptmp host and can't start a failover process
e、判断心跳节点是否存在,如果存在的话,则keeper提交degrade任务
关键日志: masterhbpath: %s exsits, next step: DegradeMaster
f、如果心跳节点不存的话,则直接进入下面的report relaylog阶段
keeper提交degrade任务
a、判断主库的resources节点下是否存在对应gjid的degrade任务,如果存在,则正常退出
关键日志 path %s already exists and return 0
b、提交degrade任务至主库的resources节点(同时提交了一个降级超时任务)
关键日志 set znode /sz_cbs_teledb/resources/rsip@132.121.214.88/rsport@8112/swjobs@132.121.214.88_8112/swjob@132.121.214.88_8112_0000000349+degrade {"gjid":"GJID_CONSIST_FAILOVER_0000000349","host":"132.121.214.88_8112","set":"set_9288878112","step":"degrade"}
主库agent处理degrade
原主库的agent watch到swjob节点后开始进行degrade任务处理,主要做的事情如下:
a、如果两次连不上数据库,则直接报degrade失败
b、设置主库为read_only,如果设置失败,则降级失败
关键日志: degradejob set global read_only error:%s\n
c、检测主库是否时read_only,如果不是,则降级失败:
关键日志 degradejob checkReadOnly error:%s\n
d、用show processlist得到当前MYSQL中正在运行的线程及其用户,把除开以下四个用户所属的其它线程通过执行KILL语句的方式杀掉system user,unauthenticated user,还有agent配置文件中的两个用户
<!--设置clusteragent 进行数据库状态检查的账户及密码-->
<agent user="agent" pass="agent_pwd" />
<!--设置主从数据复制的账户级密码-->
<repl user="sla" pass="sla_pwd" />
注1:不是主库了,GATEWAY过来执行的SQL线程要暴力地终止。
e、执行stopSlave 和resetSlaveAll (看到这里是否觉得奇怪,这个DEGRADE流程执行的主机,怎么会需要stopslave?因为这个stop slave操作只针对当前的主库是DCN备份中的从库,当它不是主库时,就不需要再用SLAVE的方式复制了。)
f、degrade流程成功,将state由degrade改为degrade success,并调用persostToZK写回到zk中去,举例如下
INFO 8300,zkcommjob.cpp:131:persistToZk,tid:0x2ac221007700,logtraceflag:swjob_answer. setOrCreate /sz_cbs_teledb/resources/rsip@132.121.214.88/rsport@8112/swjobs@132.121.214.88_8112/swjobans@132.121.214.88_8112_0000000351+degrade content {"Gtid_IO_Pos":"0-0-0","Master_Host_Port":"","Master_Log_File":"","Read_Master_Log_Pos":"","delay":"0","errorcode":"2","gjid":"GJID_CONSIST_FAILOVER_0000000351","gtid":"","history":"|begin execute","host":"132.121.214.88_8112","runinfo":"begin execute","set":"set_9288878112","step":"degradedone","updatecount":"1"}
success
g、keeper通过zk watch到ans节点的变化,调用deal_swjobans进行后续处理