


环境
hudi有很多种写入流程,使用不同的表类型、写类型(WriteOperationType)、索引类型(IndexType),流程上都会有所差异。使用flink流式写MOR表场景比较多,顺道梳理一下这个流程的细节
- hudi 0.11.1
- mor表
- write.operation=insert/upsert
- flink状态索引
整体流程
| pk1,pk4 | ===\ /=== | bucket assigner1 | ===\ /=== | write task1(pk1,pk2) |
shuffle(by PK) shuffle(by bucket ID)
| pk2,pk3 | ===/ \=== | bucket assigner2 | ===/ \=== | write task2(pk3,pk4) |
- 流中的数据先根据主键进行shuffle,由于主键的唯一性,所以同一记录后续的变更都会分配到相同的bucket assigner中
- bucket assigner确定每个主键的物理存储位置(分区+fileId),每个主键的位置保存在状态索引
ValueState中 - 数据确定了fileId(buckId)后,再进行一次shuffle,因为相同fileId的数据将会写到同一个数据文件,应由同一write task处理
- write task接收到并缓存数据,达到阀值或chekcpoint时将数据写到磁盘
桶分配
基于状态索引的tagLocation过程,即确定第条记录应该写到哪个fileId。
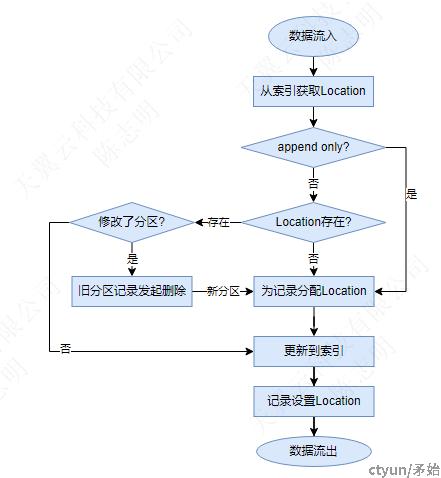
- MOR表的append和upsert流程一致,append的记录不会把location保存到索引
- 对于upsert的情况,当记录修改时变了分区,需要将旧分区中的原记录删除,同时在新分区分配新的location
如何为记录分配Location?
每个分区下的桶数量为是bucket_assigner算子的并行度,每个桶始终由多个assigner中固定的一个生成和分配,桶(fileId)与assigner之间存在映射关系,通过fileId可以判断是否属于该assigner.
例如要为记录<id1,parition1>分配bucket,id1经shuffle后由assigner1处理,流程如下: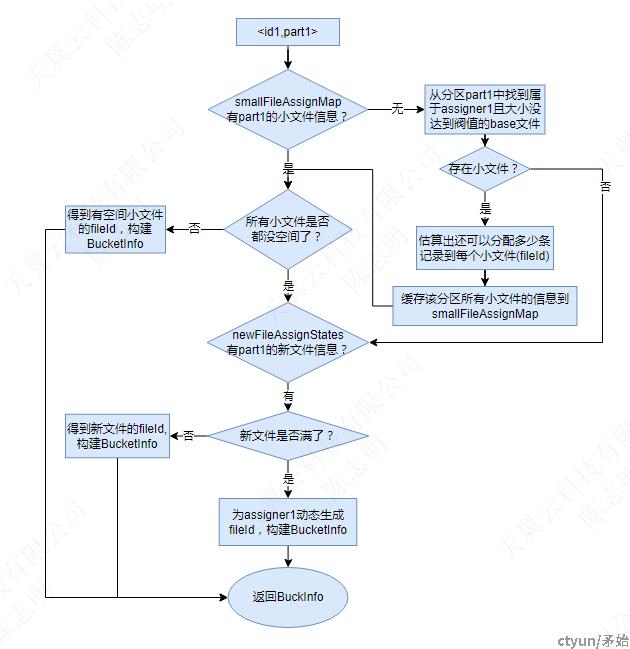
这个过程做了小文件优化,避免产生过多的小文件(重用fileId),判断文件已满参考WriteProfile</id1,parition1>
- smallFileAssignMap:缓存着当前assigner每个分区下的较久前创建的小文件信息
- newFileAssignStates: 缓存着当前assigner每个分区下的最近创建的文件信息
两个缓存对象都会在checkpoint时清空
使用注意:
- 全理设置并度
- 由于使用了flink state,须合理设置ttl和状态后端
写数据
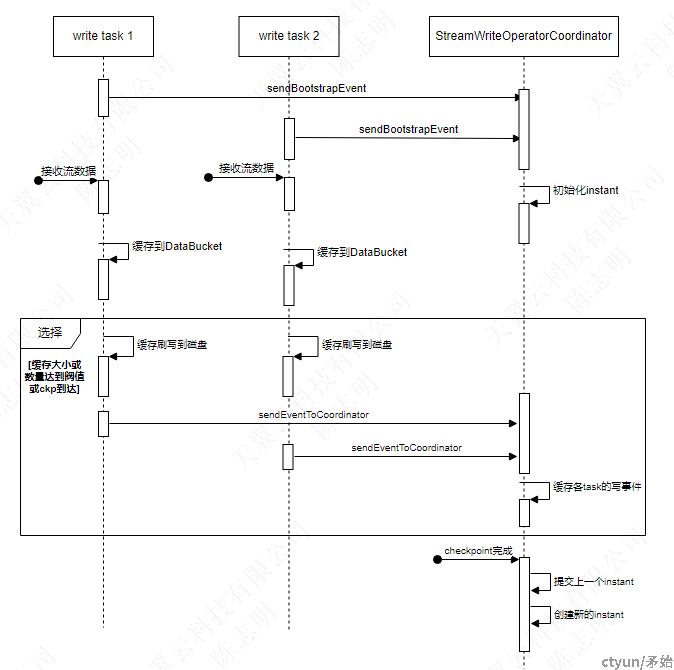
- 每次checkpoint时都会把缓存中数据刷盘,在之前如果缓存中的数据达到WRITE_BATCH_SIZE或WRITE_TASK_MAX_SIZE也会触发刷盘
- 在持续流式写过程中,
StreamWriteOperatorCoordinator作为写协作器,协调各个write task,负责初始化和推进instant、调度compaction和clustering、同步hive - 所有write task都会一直等待协作器创建新的instant成功才会执行写操作(通过扫描文件系统来发现新的instant)。
- 同一个checkpoint间隔中发生多次写产生的文件,都具有相同的instant
