


1.关系代数
关系代数即关系模式所做的代数运算,关系模式的本质就是一个二维表,垂直方向上的列就是属性,每一个表都有目个数的列;每一行就是元组行,也叫记录,代表着每一个实例(关系模式是多个实例的集合)
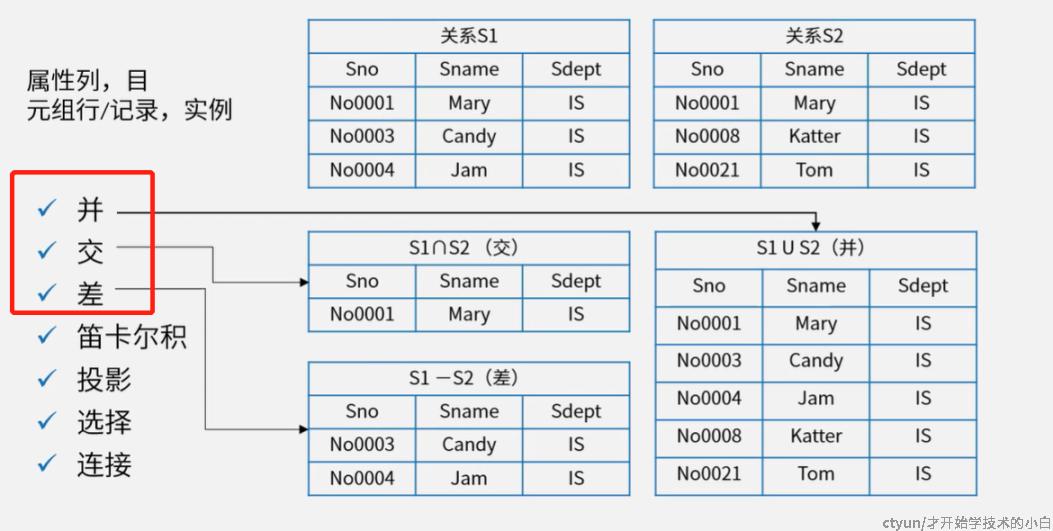
基础的运算有七个
- 并(∪):并表,如上图
- 交(∩):即取两表交集,如上图
- 差( - ):做两表查,减去被减数表所有的记录,即保留减数中被减数没有的记录
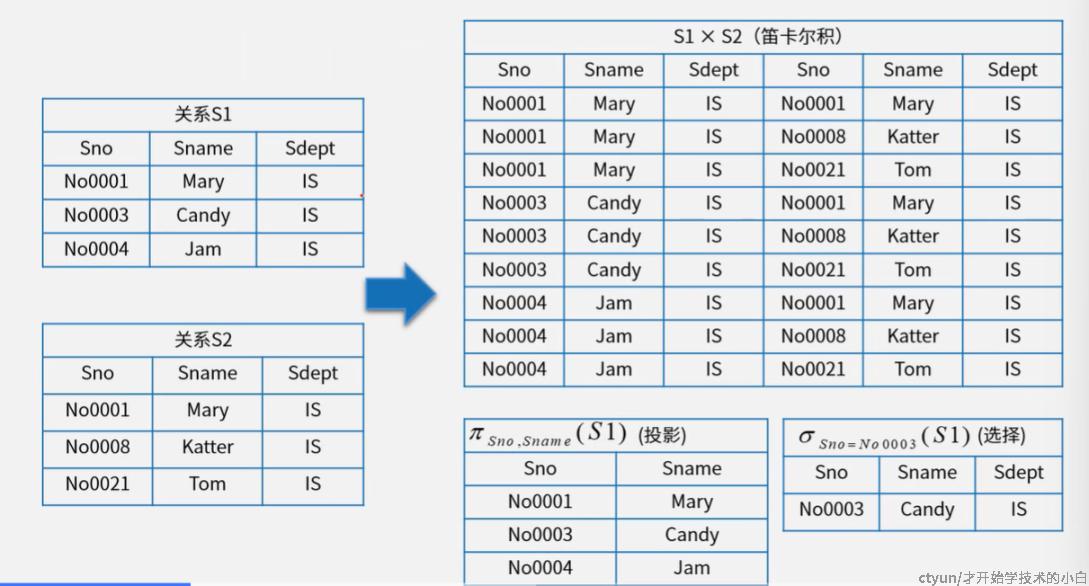
- 笛卡尔积(×):两表的结构可以异构,如下图,可以理解为表1中的每一条记录拼接表2中的所有记录,运算后的属性列为而这之和(属性名重合会标注 原表名.属性名,图里没有标注出来),元组行为二者乘积
- 投影(π):一元运算,即筛选列(属性),如下图
- 选择(σ):一元运算,即筛选行(记录),如下图
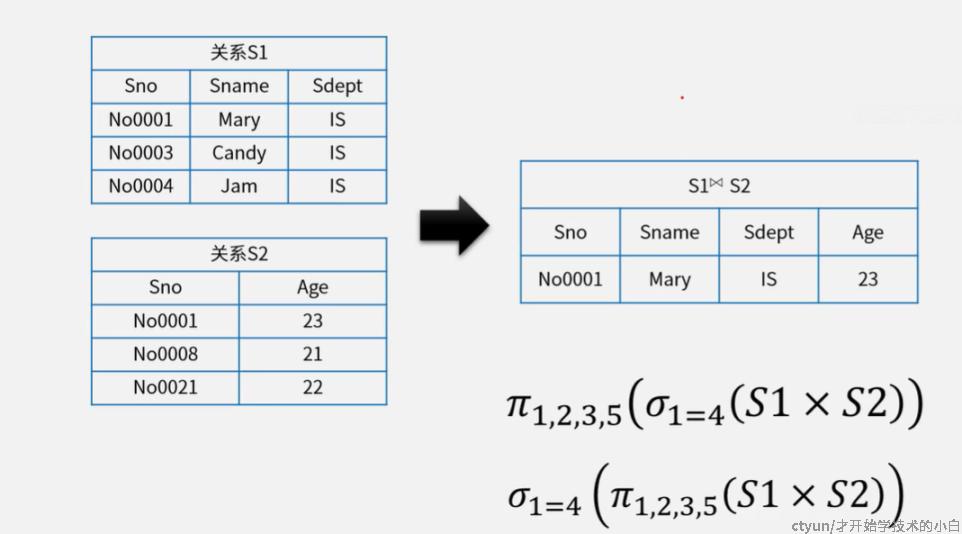
- 自然连接(⋈):一种特殊的等值连接,如下下图,属性列为两者之和减去重复列(优先列前面那个,再列后面的,重复的就不列出来),元组行一定要满足相同属性列取值相等才可以保留,效率比笛卡尔积较高
2.规范化理论
2.1 非规范化存在的问题
规范化是逻辑结构设计的一个任务,不规范化可能会有:数据冗余、更新异常(修改操作一致性问题)、插入异常、删除异常 等问题(没达到第三范式3NF,默认这些问题都会存在)
比如:
- 某个学校有5000个学生,有1000个都在一个学院,他们在数据库里的 院系 属性就都一样,一样的数据存了一千条,想要更改就很麻烦,而且也很浪费时间;
- 再比如新建了一个院,但是还没找学生,那你要存信息就存不了(插入异常)因为没主键(比如说学号)
即使规范化会使得查询效率变低,但他还是需要的
2.2 规范化理论基本概念
函数依赖:通过属性之间的转换关系来表示的,即当某个属性存在的时候,他所依赖的属性可以一起确认且唯一,表示为 X—>Y,即X可以决定Y的值
主键就是根据它可以找到所有东西,但其他东西推导不出它,所以主键的本质就是X
规范化理论的一个重点就是图示法找候选键:
- 将关系模式的函数依赖关系用“有向图”表示
- 找入度(箭头流入的数量)为0的属性,并以该属性集合为起点,尝试便利全图
- 如果可以遍历,则该属性集合为关系模式的候选键
- 如果不可以遍历,则需要尝试将一些中间节点(有入度也有出度)并入入度为0的属性集中,再次尝试
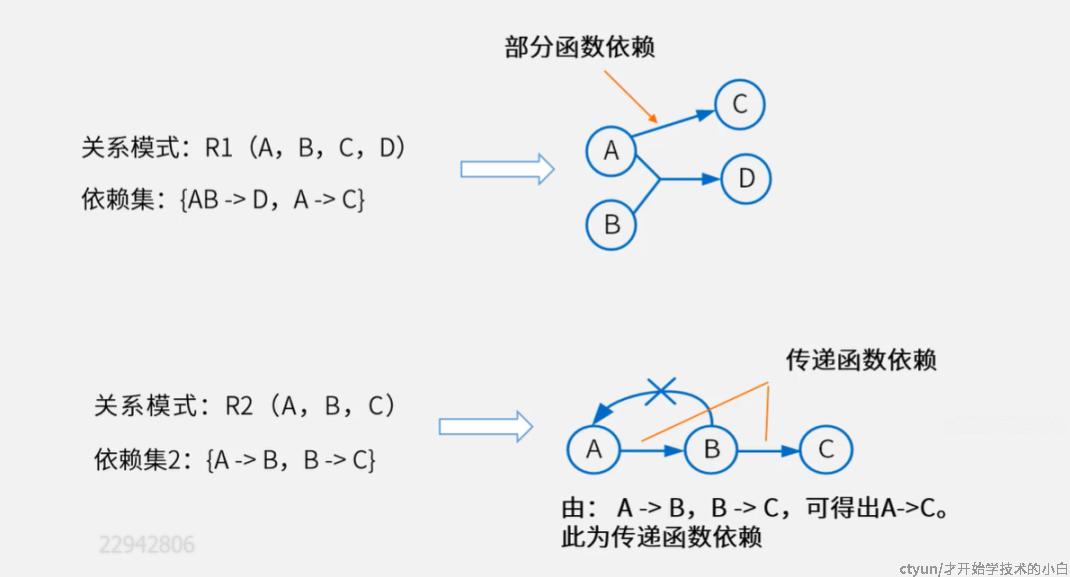
两个特殊的函数依赖关系:
- 部分函数依赖:只依赖候选键中的一部分
- 传递函数依赖:A—>B—>C,进而可以得出A—>C
2.3 Armstrong公理系统
有三条基本定律,比如说某个关系模式R<U, F>,U为属性集合,F为依赖集合(关系)
- 自反律:如Y⊆X⊆U,则X—>Y(身份证可以确认身份证号/姓名)
- 增广律:如Z⊆U且X—>Y,则XZ—>YZ(身份证可以确认姓名,身份证+户口本也可以确认姓名+户口本)
- 传递律:如X—>Y且Y—>Z,则X—>Z(身份证可以确认身份证号,身份证号可以确认出生年月,即身份证可以确认出生年月)
还有三条推广定律:
- 合并规则:如X—>Y且X—>Z,则X—>YZ
- 伪传递规则:如X—>Y且WY—>Z,则XW—>Z
- 分解规则:如X—>Y且Z⊆Y,则X—>Z
2.4 范式判断
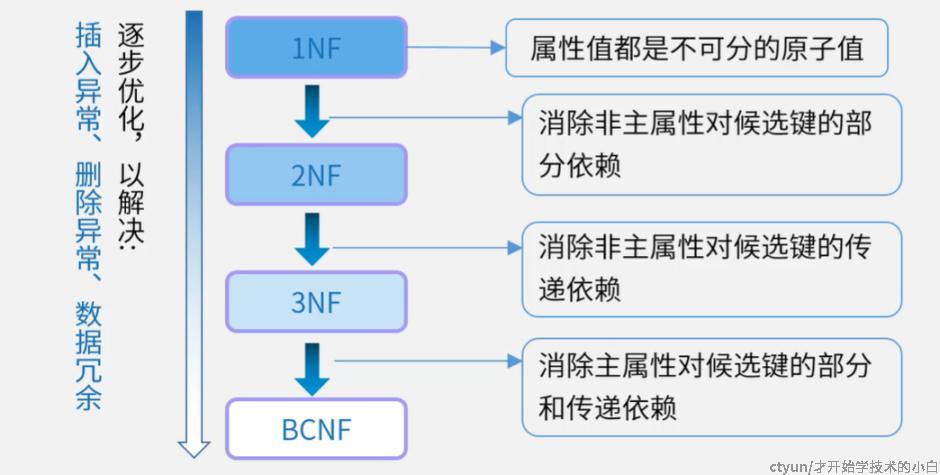
主要的有以下四类范式:第一/二/三范式和BC范式,越往下设计的越规范
一些属性的定义:
- 复合属性(姓名)、
- 多值属性(一个人有几个电话)、
- 派生属性(知道销售量和单价可以计算出销售额)、
- NULL属性(还没定就设置为null)
范式的说明:
- 没有达到第一范式没办法建表:在关系模式R中所有域都只包含原子值,一般没说明都代表不可再分(比如姓名我们经常一起用,但实际上可以再分为姓氏和名字)
- 第二范式:在第一范式的前提下,每一个非主属性对主键的依赖不存在部分依赖,一般只能通过拆表来实现
- 第三范式:在第二范式的前提下,每一个非主属性对主键没有传递依赖,一般只能通过拆表来实现
- BC范式:一般是在第三范式的前提上再考虑,每个依赖的决定因素(即箭头左侧)必定包含R的某个候选码
2.5 模式分解
刚刚提到拆表是有效提高规范化的办法,拆表这个动作,我们就叫做模式分解。
模式分解的依据主要是两个:
- 是否保持了原有的函数依赖:拆分后的所有模式 的函数依赖集合 的集合,与拆分前的是等价的(即相互逻辑蕴含,允许可以推导出的冗余函数依赖不存在),就称为分解后的模式保持了分解前的模式
- 是否无损:无损联接分解,即分解后的模式可以通过自然连接/投影等运算可以还原
判断无损可以用图示法/公式法,其中后者只适用于分解为两个的情况,用的比较少


