


1.数据库模式
数据库体系结构分为 三级模式 + 两层映射关系,如下图
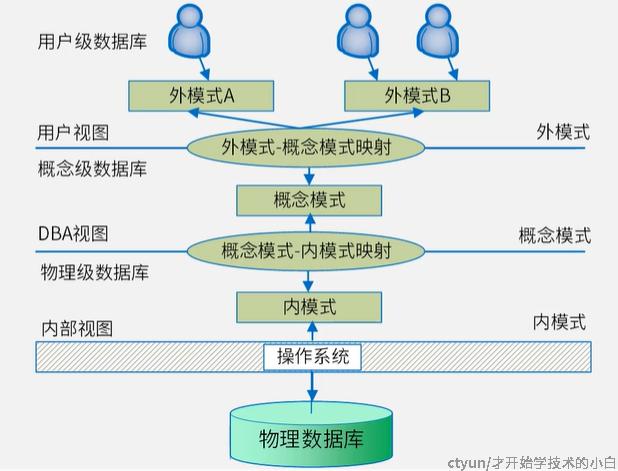
对于我们程序员/用户来说,我们看到的是数据库的用户视图,在外模式这个层,其数据来源是概念模式,所以有一个外模式-概念模式的映射(保证了逻辑独立性,即外部应用程序与概念模式中的基本表相互独立,如果有一方有变动,只需要修改映射表即可)
概念模式(又叫逻辑模式,简称模式),是数据库的核心,存储着基本表,包含了所有数据的逻辑结构和特征描述,基本表的内容映射了底层的文件,因此有 概念模式-内模式映射(保证了物理独立性,即内模式的物理程序发生变化的时候,应用程序也不需要发生变化,比如应用迁移的时候不需要改数据库,只要改映射即可)
内模式(又叫存储模式/物理模式)对应的是基本的存储文件
如果为关系型数据库,我们创建的都为关系表,关系表有三种类型:
- 基本关系(通常又称为基本表/基表):实际存在的表,存储数据的逻辑表示,比如执行创建sql出来的表
- 查询表:查询结果对应的表,即执行查询语句之后查出来的表
- 视图表:由基表或其他视图表导出的表,本身不独立存储,数据库只存放他的定义,因此也叫虚表
数据库的视图:虚表,它的内容由查询来定义(仅保存sql查询语句),视图除了没有真实的存储这些数据(动态生成所需要的数据)之外,都跟真实的表一样(但是性能上看不是很好)
视图的优点:
- 简化用户操作
- 用户得以从多种角度看待统一数据
- 对重构数据库提供了一定程度的逻辑独立性(只需要修改视图和概念模式之间的映射关系即可)
- 对机密数据提供安全保护(视图只读不可写)
如果视图存了下来,他就叫做物化视图,且原始表中的数据更新,物化视图也会更新(但更新太多了就影响性能了,因此它只适合多查询、少更新的情况)
2.分布式数据库
分布式是对应集中式来说的,集中式数据库就是把数据放在一台机子上,但分布式数据库会放在不同的物理节点上,因此访问数据的时候就可以优先请求临近的节点,效率有所提升,也起到了一定的备份作用
分布式数据库的四大特性:
- 数据独立性:除了数据的逻辑独立性(外部应用程序与概念模式中的基本表相互独立)和物理独立性(内模式的物理程序发生变化的时候,应用程序也不需要发生变化)外,还有分布独立性(分布透明性),即无论数据是怎么存的存在哪,我们都不需要修改应用程序
- 集中于自治共享结合的控制结构:在局部的数据库节点上有局部的管理系统(DBMS),具有自治的功能;并且系统有集中控制机制,用来协调各个DBMS的工作,执行全局应用
- 适当增加数据冗余度:提高了系统的可靠性和可用性(数据/节点有灾备),同时也能提高系统性能
- 全局一致性、可串行性、可恢复性
分部署数据库层次,一方面是有了全局和局部的区别(全局概念模式体现了数据的整体逻辑结构),另一方面是有了分片模式和分布模式
- 分片模式:将一个数据库来进行分片,有垂直分片、水平分片、混合分片等
- 分布模式:分片之后这些东西放置在哪个具体的节点,就由分布模式决定并放在某一个局部上
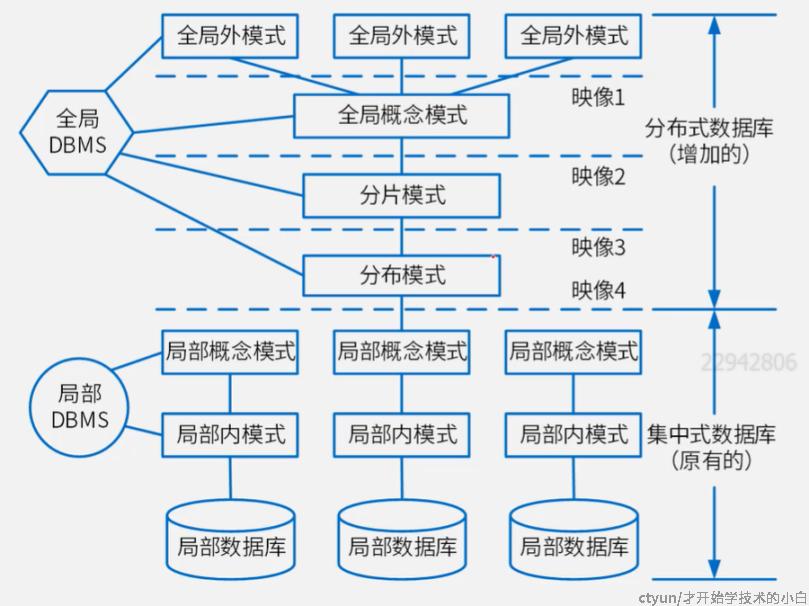
因此我们就有全局的DBMS、局部的DBMS,分布称为LDBMS、GBDMS,加起来我们称为DDBMS
分片的本质就是把一大堆数据切碎,这样方便放在不同的节点:
- 水平分片:将不同的元组分开,放在不同的子集上
- 垂直分片:将不同的属性列分开,放在不同的子集上
- 混合分片:即切块,有元组也有属性
分片透明性:用户不需要关心数据是如何分片的
复制透明性:有些数据是会存多个副本的,而且需要不定期更新,但用户不需要关心
位置透明性:用户不需要知道数据具体放在哪个节点
逻辑透明性(局部映像透明性):用户不需要知道DBMS到底支持哪种数据模型/操作语言
分部署数据库的两阶段提交协议(2PC)
- 表决阶段,目的是形成一个共同的决定(所有的局部数据库提交自己的决议,都通过了才会全局提交)
- 执行阶段,目的是实现这个协调者的决定
3. 数据库设计模式
设计过程:
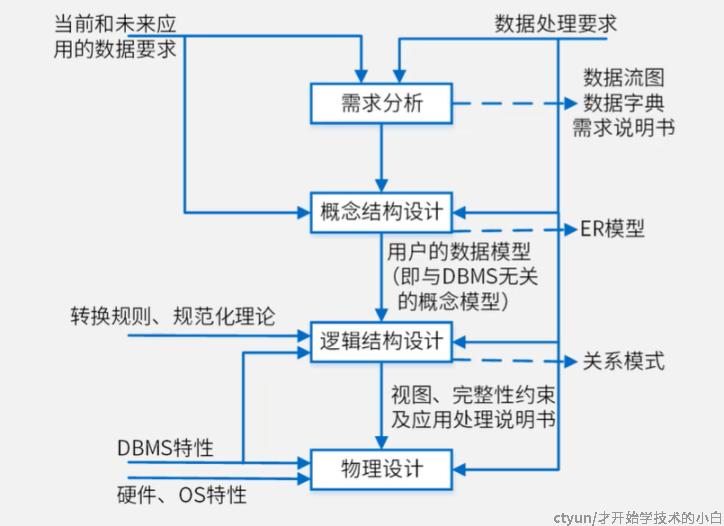
需求分析:参考 当前和未来应用的数据要求 + 数据处理要求,输出的是数据流图(数据的变换过程)、数据字典(数据的详细含义)和需求说明书
概念结构设计:参考的是需求分析的输出内容,是对现实世界的抽象,得到的是ER模型(实体关系图);与DBMS无关
逻辑结构设计:参考ER模型,输出的是数据模型,在关系型数据库中,这个数据模型为关系模式(又叫 关系表,基本表就参考这个来建立)
物理设计:完成对数据库相应分布形式、存储形式、访问形式的设计,要考虑硬件和操作系统的特性
4.概念结构设计
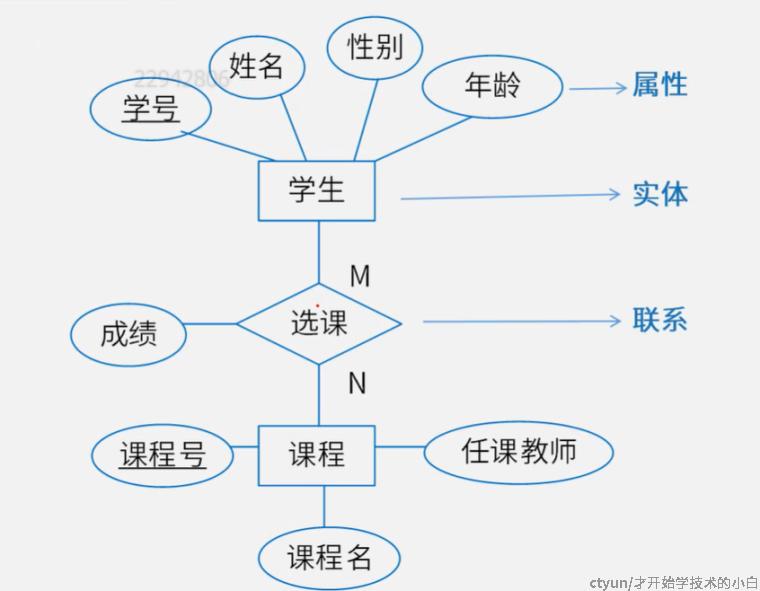
ER图,是实体联系图,如下图:
实体与实体之间能够存在联系,同时实体/联系也有很多属性(特征值),同时不同的实体集之间也会有联系:
- 一对一的联系,比如一个班级实体集有十个班,然后他与对应的十个班主任有对应关系,这种对应关系就是一对一的联系
- 一对n/n对一的联系,将班主任换成学生即为一对多
- n对m的联系,比如学生选修课程,可以多选一、一选多、多选多
概念结构设计的步骤:
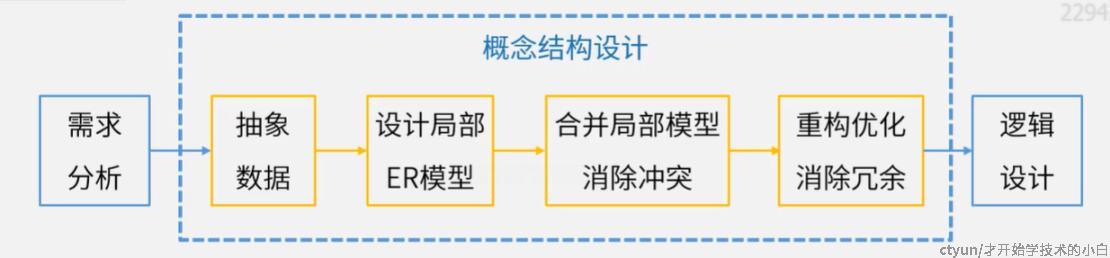
所谓的合并局部模型,就是集成多个ER图的过程,有两个方法:
- 多个局部ER图一次集成
- 逐步集成,用累加的方式一次集成两个局部ER图
解决冲突的办法:
- 属性冲突:可能是属性域冲突(属性值定义、取值范围、类型等),也可能是属性取值(比如单位)冲突
- 命名冲突:包括同名异义(比如docter和docter),也可能是异名同义(比如教师和老师)
- 结构冲突:可能是同一对象在不同应用中具有不同的抽象,或者同一个实体在不同的局部ER图中包含的属性个数和属性排列次序不完全相同
5.逻辑结构设计
5.1 关系模型基本概念
关系模型的本质就是数据模型,数据模型有三个要素:
- 数据结构
- 数据操作
- 数据的约束条件
数据模型也可以大致分为四种:
- 层次模型,类似树状图
- 网状模型,类似拓扑图
- 面向对象模型:以对象为单位组织的数据模型
- 关系模型:有两个集合(U,F),U代表它的属性集合,F代表函数依赖集合;也是典型的二维表结构,表名为关系模型名称,属性对应类名,每一个实例对应行
比如,一个关系模型拥有四个属性:学生(学号,姓名,年龄,班级编号),他有以下几个重要属性:
- 目或度:属性的个数,本例为4
- 候选码(候选键,key):表示的是能够唯一标识元组、且无冗余(意思是一个能标识绝不用多个)的属性集合。本例中,可以是学号,但不可以是姓名,如果有身份证号也可以是身份证
- 主码(主键):从候选键中任选一个
- 主属性与非主属性:组成候选码的属性就是主属性,其他的为非主属性
- 外码(外键):其他关系的主键,比如选课关系和我们示例中的学生关系由关联,选课关系的主键就叫做外键
关系模型的完整性约束:
- 实体完整性约束:规定基本关系的主属性不能取空值(唯一且非空)
- 参照完整性约束:关系与关系间的引用,其他关系的主键或空值
- 用户自定义完整性约束:应用环境来决定,比如自定义记录性别的时候只能是male或者female
- 触发器:一个比较复杂的完整性约束
5.1 逻辑结构设计
主要就是把ER图转化为数据模型(关系模型),主要步骤如下图:
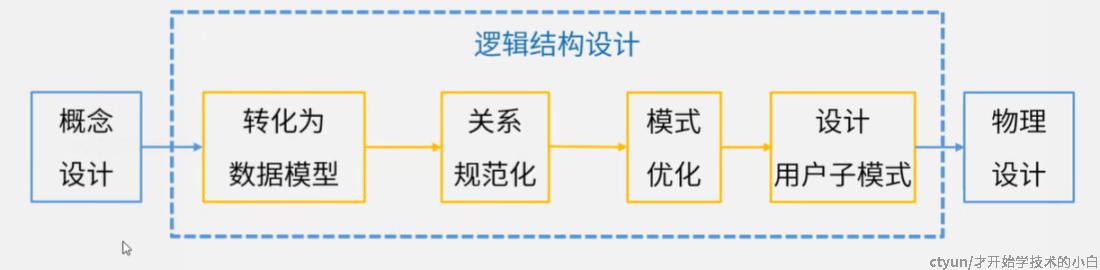
详细来说步骤如下:
- ER图向关系模型的转换:
- 实体向关系模型的转换
- 联系向关系模型的转换
- 关系模型的规范化
- 确定完整性约束(保证数据正确性)
- 用户视图的确定(提高数据的安全性和独立性)
- 根据数据流图确定处理过程使用的视图
- 根据用户类别确定不同用户使用的视图
- 应用程序设计
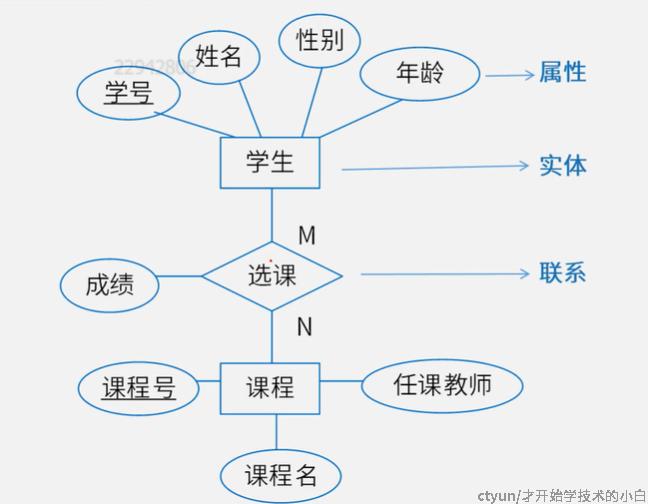
ER图向关系模型的转换有一些比较固定的设计原则,以上图为例:
- 一个实体必须转为一个关系模式
- 联系可以并入实体,也可以转为关系模型
- 一对一联系:
- 独立的关系模式,并入两端实体的主键(任意一端)及自己的属性,上图情况,学生和课程就可以独立作为两个关系模型,选课也单独独立出来,可以用课程号做主键,也可以用学号作为主键(任一端主键)
- 归并入任意一端:并入另一端的主键及自己的属性,上图情况,可以把课程并入学生并作为学生的一个属性,主键还是学号,可以并入课程这个实体,用课程号做属性(主键保持不变)
- 一对多联系:
- 独立的关系模式:实际上的学生有多个,所以是一对多的关系,联系独立的时候,就需要采用多的那一段的主键,这个例子里是学生,因为一个课程/考试对应多个学生(采用多端主键)
- 归并入多端:同样可以归并,但要归入多端(主键保持不变)
- 多对多关系:比较复杂,只能独立
- 独立的关系模式:并入两端主键(主键为两端主键的组合键)
