


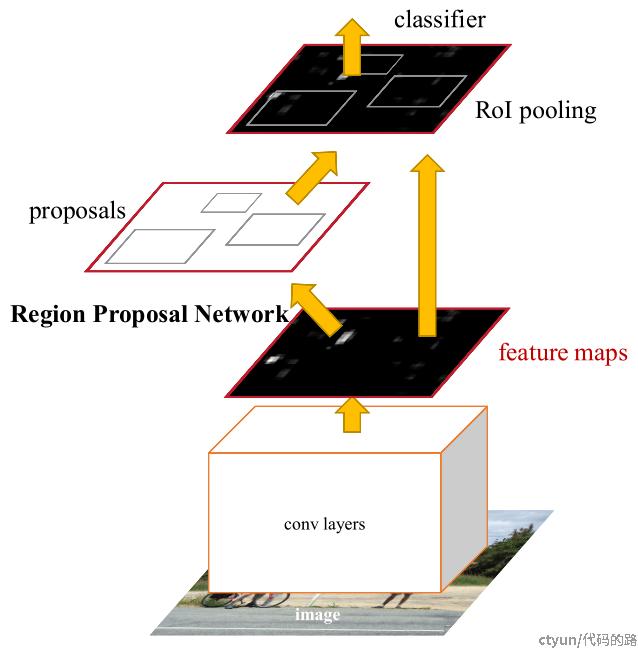
区域建议网络(RPN)首先在faster rcnn中提出。
得到用来预测的feature map
生成Anchors
anchor是固定尺寸的bbox。具体做法是:把feature map每个点映射回原图的感受野的中心点当成一个基准点,然后围绕这个基准点选取k个不同的尺寸和比例的anchor。对于W×H大小的卷积feature map(通常为2400),总共有W×H×k个锚点。默认使用3个尺度和3个纵横比,在每个滑动位置上产生k=9个anchor。在feature map上的每个特征点预测多个region proposals。例如对于像素点个数为 51×39 的一幅feature map上就会产生 51×39×9 个候选框。虽然anchors是基于卷积特征图定义的,但最终的 anchors是相对于原始图片的。
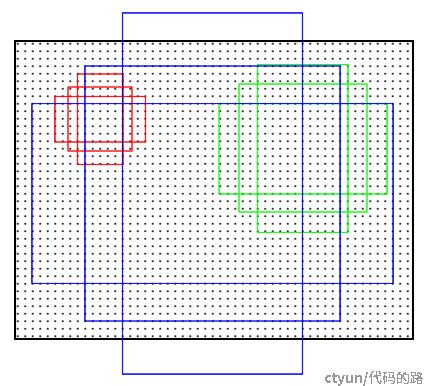
图1 九个候选框(anchor)示意图
针对该像素点的每个候选框需要判断其是不是目标区域,如果是目标区域,其边框位置如何确定,具体过程如图2所示,在RPN头部 ,通过以下结构生成 k个anchor。
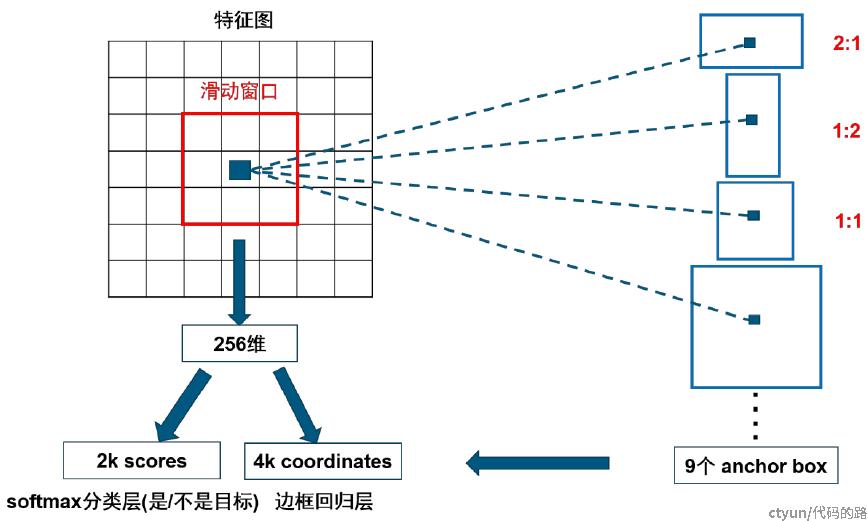
图 2 RPN 过程示意图
如图2所示,针对特征图中的某一个位置的像素点,对应会有9个候选框。因为输入RPN中有256个通道的特征图,所以要同时对每个通道该位置的像素点都使用不同的3×3的滑动窗口进行卷积,最后将所有通道得到的该位置像素点的卷积值都加起来,得到一个新的特征值,最终使用256组这样的3×3的卷积核,就会得到一个新的256维的向量,这个256维的向量就是用来预测该位置的像素点的,该像素点对应的9个候选框共享这256维向量。
256维向量后面对应两条分支,一条目标和背景的二分类(classification),通过1×1×256×18的卷积核得到 2k 个分数,k等于候选框的个数9,表示这9个anchor是背景的score和anchor是目标的score。如果候选框是目标区域,就去判断该目标区域的候选框位置在哪,这个时候另一条分支就过1×1×256×36的卷积核得到4k个坐标,每个框包含4个坐标(x,y,w,h),就是9个候选区域对应的框应该偏移的具体位置Δxcenter,Δycenter,Δwidth,Δheight。如果候选框不是目标区域,就直接将该候选框去除掉,不再进行后续位置信息的判断操作。
分类分支
考察训练集中的每张图像(含有人工标定的gt box) 的所有anchor划分正负样本:
(1)对每个标定的gt box区域,与其重叠比例最大的anchor记为正样本,保证每个gt至少对应一个正样本anchor
(2)对(1)中剩余的anchor,如果其与某个标定区域重叠比例大于0.7,记为正样本(每个gt可能会对应多个正样本anchor。但每个正样本anchor只可能对应一个gt;如果其与任意一个标定的重叠比例都小于0.3,记为负样本。
回归分支
x,y,w,h分别表示box的中心坐标和宽高,x,,x分别表示predicted box, anchor box, and ground truth box (y,w,h同理)表示predict box相对于anchor box的偏移,表示ground true box相对于anchor box的偏移,学习目标就是让前者接近后者的值。
在 RPN中部,分类分支(cls)和边框回归分支(bbox reg)分别对这堆anchor进行各种计算。在RPN末端,通过对两个分支的结果进行汇总,来实现对anchor的初步筛除(先剔除越界的anchor,再根据cls结果通过非极大值抑制(NMS)算法去重)和初步偏移(根据bbox reg结果),此时输出的都bbox改头换面叫 Proposal 了
偏移公式如下。An就是anchor的框,pro就是最终得出回归后的边界框,到这里我们的proposals就选好了:
非极大值抑制(Non-maximum suppression)
由于anchor一般是有重叠的overlap,因此,相同object的proposals也存在重叠。为了解决重叠proposal问题,采用NMS算法处理:两个proposal间IoU大于预设阈值,则丢弃score较低的proposal。
IoU阈值的预设需要谨慎处理,如果IoU值太小,可能丢失objects的一些 proposals;如果IoU值过大,可能会导致objects出现很多proposals。IoU典型值为0.6。
Proposal选择
NMS处理后,根据sore对top N个proposals排序。在Faster R-CNN论文中 N=2000,其值也可以小一点,如50,仍然能得到好的结果。
