


0.引言
HPC(High Performance Computing,以下简称HPC)是一个领域,试图在任何时间点和技术上对于相关技术、方法和应用等多种方面实现最大的计算能力;换而言之其目的就是求解一类问题的答案,这类问题往往无法通过经验、理论甚至广泛可用的商业计算机/服务器来求解(比如说需要的PB级别数据计算的科研任务、生物科学的DNA解析、难以分析的机器学习模型);HPC的载体是“超级计算机/超级计算系统/平台”,用他们来尽可能快的执行各种计算问题或应用程序,这个执行的过程我们也称之为超级计算;
总而言之,HPC是一个领域,超算平台是他的载体,超级计算是他完成计算任务的过程。而我们常说的HPC产品略有不同,它提供了一种性能卓越、稳定、安全、便捷的(云)计算服务、通过各种互联技术将多个计算机系统连接在一起,利用这些被连接系统的综合计算能力来处理大型计算问题,所以HPC又被称为高性能计算集群。
本文将主要介绍一种使用slurm(Simple Linux Utility for Resource Management,以下简称slurm)——一种开源的HPC资源管理与作业调度的基础软件,来进行作业调度并在多虚拟机节点上部署与配置计算集群的方法。
1.slurm的基本含义
1.1 slurm的定义与功能
slurm是一种开源的、具有容错性和高度可扩展的Linux集群超级计算系统资源管理和作业调度系统。具体来说,计算集群使用slurm对资源和作业进行管理和调度,减少计算任务间相互干扰,提高集群运行效率。2016年世界十大超算系统,其中就有五个是使用slurm来进行管理的,甚至有众所周知的2016年冠军超算——神威太湖之光。
slurm给超算系统的提供了三个关键功能:
1.为用户分配一定时间的专享或非专享的资源(计算机节点),以执行作业(Job)
2.提供了用于启动、执行、监测在节点上运行的作业的框架
3.为作业队列合理地分配计算资源
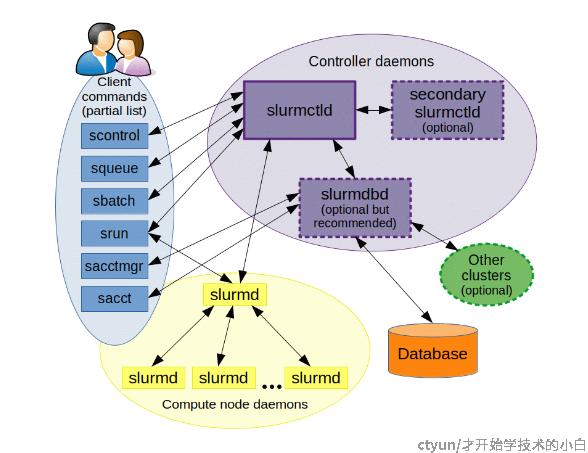
1.2 slurm的基本架构
在slurm计算集群系统,众多节点将会分为master节点(主节点/管控节点),compute节点(计算节点)以及部分集群会有client节点(登录节点),它专门用来给用户执行各种作业调度与资源部署的指令,但多数情况是client节点和master节点部署在同一个节点上以简化部署。
slurm包含四种服务(守护进程),在各个节点上有不同的部署分布:
1.slurmctld服务:只运行于master节点,作为中心管理器用于监测资源和作业
2.slurmd服务,主要运行于compute节点,作用是接收调度,承担实际的计算负载;
3.slurmdbd数据库服务,通常运行于master节点,可以将多个slurm管理的集群的记账信息记录在同一个数据库中
4.slurmrestd服务,通常运行于master节点,用来提供REST API与Slurm进行交互
2.虚拟机的安装与配网
可以参考本人专栏文章:https://www.ctyun.cn/developer/article/353763363754053
准备至少两台虚拟机来分别模拟master和compute节点即可
3.slurm的安装与部署
3.1 环境与版本
| 软件工具 | 版本号 |
| Xshell |
7.0.0025 |
| VituralBox | 6.1.39 |
| Cent OS | 7.6 minimal |
| slurm | 20.11.9 |
| mariadb | 5.5.68 |
| munge | 0.5.11-3 |
3.2 安装前的准备工作
3.2.1 节点信息一览
|
节点类型 |
主机名 |
IP |
系统版本 |
|
master |
master |
192.168.206.138 |
centos7.6 |
|
compute |
compute |
192.168.206.139 |
centos7.6 |
3.2.2 修改节点hosts
修改所有节点/etc/hosts文件,添加所有节点ip和主机名映射,即执行:
echo -e "\n192.168.223.66 master\n192.168.223.67 compute" >> /etc/hosts
#可以用cat来检查
cat /etc/hosts
#设置两台虚拟机的hostname
hostnamectl set-hostname master
hostnamectl set-hostname compute
3.2.3 关闭防护墙同时禁止防火墙开机启动
在所有节点执行如下指令,若无反应,重启虚拟机即可
systemctl disable firewalld --now
3.2.4 用户资源限制
在所有节点执行如下指令,修改默认的用户资源限制
sed -i '$i\* hard nofile 1000000\n* soft nofile 1000000\n* soft core unlimited\n* soft stack 10240\n* soft memlock unlimited\n* hard memlock unlimited' /etc/security/limits.conf
3.2.5 修改时区
配置为上海时区,若安装过程中已完成配置,可忽略该步骤(可用date -R查看本地时间来验证)
ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
3.2.6 时间同步
munge要求各个节点时间误差在5min内,可以使用ntp或chrony实现时间同步,这里使用ntp
# 首先安装ntp
yum -y install ntp
# 安装完毕之后,启动服务
systemctl start ntpd.service
# 设置开机自启动
systemctl enable ntpd.service我们拥有两台服务器:192.168.206.138,192.168.206.139
第一台服务器192.168.206.138(master),作为ntpserver,设置为同步外网时间(ntpd服务开启时默认同步)
与此同时,需要设置允许内网网段可以连接,将该服务器作为内网的时间同步服务器,因此进行如下简单配置:
修改/etc/ntp.conf文件,添加如下信息,表示允许223网段来同步此服务器
vi /etc/ntp.conf
restrict 192.168.206.0 mask 255.255.255.0 #添加此行第二台服务器192.168.206.139,作为ntpclient,设置为同步上面的ntpserver,在节点上做如下配置:
修改/etc/ntp.conf文件,注释掉外网时间服务器,添加本地服务器即可
vi /etc/ntp.conf
server 192.168.206.138 #添加此行
#以下四行为外网时间服务器,注释掉
# server 0.centos.pool.ntp.org iburst
# server 1.centos.pool.ntp.org iburst
# server 2.centos.pool.ntp.org iburst
# server 3.centos.pool.ntp.org iburst设置后,重启ntpd服务,通过ntpstat检查效果
systemctl restart ntpd
ntpstat注:重置刚刚完成时,主机是正常的(连接的是ntp外网服务器),但compute显示正在重启中;重置完成几分钟后再观察,发现均正常,说明同步成功
3.2.7 设置SSH免密登录
配置master节点以实现ssh免密码登录到其他节点(compute)
在master节点执行
#执行后按三次回车,意味着全部执行默认设置
ssh-keygen -t rsa
#这里的compute可以替换为自己设置的compute节点名称;
#第一次执行的时候需要输入root密码,如果第二次执行显示连接建立成功
ssh-copy-id root@compute
3.2.8 创建用户
因为munge安装后会自动创建munge用户,为了避免不同节点munge用户的uid、gid不一致,所以提前创建用户,master和compute都需要执行,ID保持一致
#创建munge用户
export MUNGE_USER_ID=2000
groupadd -g $MUNGE_USER_ID munge
useradd -m -c "MUNGE User" -d /var/lib/munge -u $MUNGE_USER_ID -g munge -s /sbin/nologin munge
#创建slurm用户
export SLURM_USER_ID=2001
groupadd -g $SLURM_USER_ID slurm
useradd -m -c "SLURM workload manager" -d /var/lib/slurm -u $SLURM_USER_ID -g slurm -s /bin/bash slurm
3.2.9 安装依赖软件
yum -y install mailx
#epel源
yum -y install epel-release
#munge
yum -y install munge munge-libs munge-devel
#mariadb(仅在master节点安装)
yum -y install mariadb-server mariadb-libs mariadb-devel
#slurm依赖;本文部署的slurmrestd支持不使用jwt token进行认证,所以不能安装 libjwt-devel 依赖
yum -y install gcc python3 readline-devel mysql-devel perl-ExtUtils-MakeMaker pam-devel http-parser-devel json-c-devel libyaml-devel
#open-mpi构建时依赖 gcc-c++
yum -y install wget git vim gcc-c++ bzip2
3.2.10 配置munge
注意:如果munge版本 >= 0.5.15,需要使用 sudo -u munge create-munge-key 生成key文件(而不是create-munge-key),执行后会在/etc/munge目录下生成munge.key
#在master节点创建密钥
create-munge-key
#在master节点执行如下命令,将生成的munge.key传输到其他节点
#将compute替换为自己compute节点的hostname
scp -p /etc/munge/munge.key compute:/etc/munge
#在计算节点执行如下命令,将munge.key属主改为munge用户
#munge.key的属主和属组应该为munge,且文件权限应该为0600
chown munge:munge /etc/munge/munge.key
#启动munge:在所有节点执行如下指令,将munge配置为开机启动,同时启动munge
systemctl enable munge --now
#查看munge运行状态是否正常
systemctl status munge
3.2.11 配置mariadb(仅在master节点)
#修改my.cnf,slurmdbd建议配置innodb参数
sed -i '/\[mysqld\]/a\innodb_buffer_pool_size=1024M\ninnodb_log_file_size=64M\ninnodb_lock_wait_timeout=900' /etc/my.cnf
#启动mariadb
systemctl enable mariadb --now
#配置默认root用户(因为是第一次没有root密码,直接回车,是否设置root密码y,设置成123456、移除anonymous用户Y、禁止root远程登录Y、移除test数据库Y,reload privilege tables now :Y)
mysql_secure_installation
#配置slurmdbd用户:创建slurm用户,密码123456,依次执行以下代码
mysql -uroot -p123456
create user 'slurm'@'%' identified by '123456';
grant all privileges on *.* to 'slurm'@'%' identified by '123456';
flush privileges;
exit
3.3 安装slurm
3.3.1 master节点的安装
本文档采用的slurm版本为20.11.9,对应链接:
https://download.schedmd.com/slurm/slurm-20.11.9.tar.bz2
也可以使用其他版本的slurm,进入官网查看:
https://www.schedmd.com/downloads.php
#输入命令下载slurm:
wget https://download.schedmd.com/slurm/slurm-20.11.9.tar.bz2
#解压
tar -jxf slurm-20.11.9.tar.bz2
cd slurm-20.11.9
#配置
export PREFIX=/opt/slurm/v20.11.9
./configure --prefix=$PREFIX
#构建、安装
make && make install
mkdir -p $PREFIX/etc/
find etc |grep conf|xargs -i cp -v {} $PREFIX/etc/
mv $PREFIX/etc/slurm.conf.example $PREFIX/etc/slurm.conf
mv $PREFIX/etc/slurmdbd.conf.example $PREFIX/etc/slurmdbd.conf
mv $PREFIX/etc/cgroup.conf.example $PREFIX/etc/cgroup.conf
find etc |grep service$ | xargs -i cp -v {} /usr/lib/systemd/system
echo -e '#!/bin/bash\nexport SLURM_HOME=/opt/slurm/v20.11.9\nexport PATH=$SLURM_HOME/sbin:$SLURM_HOME/bin:$PATH' >> /etc/profile.d/slurm.sh
source /etc/profile修改slurm.conf:
mkdir -p $PREFIX/var/spool
chmod 0755 $PREFIX/var/spool
chown -R slurm:slurm $PREFIX/var/spool
mkdir -p $PREFIX/var/run
mkdir -p $PREFIX/var/log
#如果master节点也作为compute节点,则在master节点执行该步骤,本文档案例执行了
sed -i "s/NodeName=linux\[1-32\] Procs=1 State=UNKNOWN/$(slurmd -C | head -n 1)/g" $PREFIX/etc/slurm.conf
sed -i "s#AuthType=auth/munge#AuthType=auth/none#g" $PREFIX/etc/slurm.conf
sed -i "s/#AccountingStorageType/AccountingStorageType/g" $PREFIX/etc/slurm.conf
sed -i "s#/var/spool/slurm#$PREFIX/var/spool#g" $PREFIX/etc/slurm.conf
sed -i "s#/var/run#$PREFIX/var/run#g" $PREFIX/etc/slurm.conf
sed -i "s#/var/log#$PREFIX/var/log#g" $PREFIX/etc/slurm.conf修改slurmdbd.conf
chown slurm:slurm $PREFIX/etc/slurmdbd.conf
chmod 0600 $PREFIX/etc/slurmdbd.conf
sed -i "s/StoragePass=password/StoragePass=123456/g" $PREFIX/etc/slurmdbd.conf
sed -i "s#AuthType=auth/munge#AuthType=auth/none#g" $PREFIX/etc/slurmdbd.conf
sed -i "s#/var/run#$PREFIX/var/run#g" $PREFIX/etc/slurmdbd.conf
sed -i "s#/var/log/slurm/slurmdbd.log#$PREFIX/var/log/slurmdbd.log#g" $PREFIX/etc/slurmdbd.conf修改slurmrestd.service
sed -i "s/^ExecStart/#ExecStart/g" /usr/lib/systemd/system/slurmrestd.service
sed -i ':a;N;$!ba;s/#ExecStart/ExecStart/2' /usr/lib/systemd/system/slurmrestd.service启动slurm服务
systemctl daemon-reload
systemctl enable slurmdbd --now
systemctl enable slurmctld --now
systemctl enable slurmd --now
systemctl enable slurmrestd --now
#检查服务状态
systemctl status slurmdbd slurmctld slurmd slurmrestd此时可以看到四个服务全部都是actived,即激活完成:
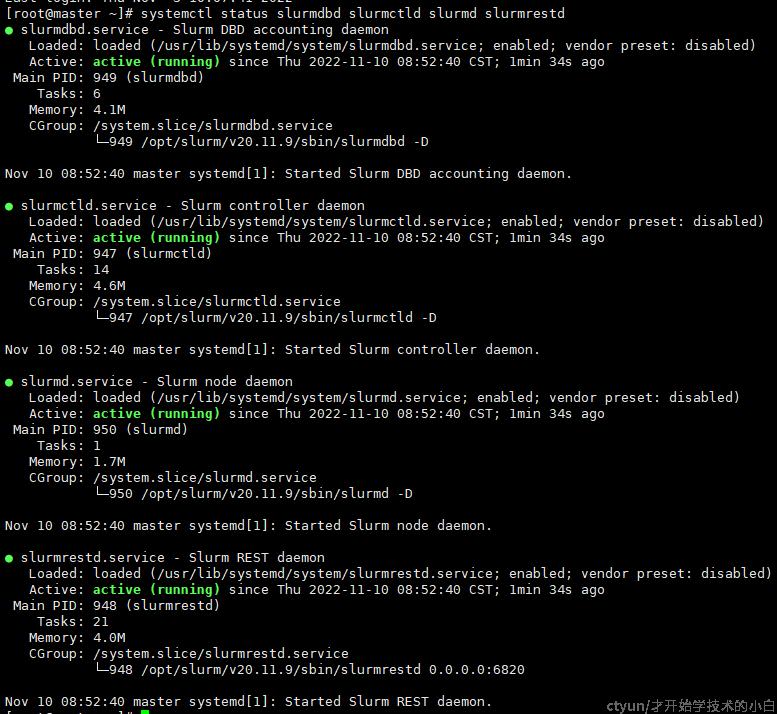
如果出现failed情况,则需要通过日志查看哪步配置出错
slurmctld的日志,/opt/slurm/v20.11.9/var/log/slurmctld.log
slurmd的日志,tail -100f /var/log/messages
slurmrestd的日志,tail -100f /var/log/messages
slurm配置位置,/opt/slurm/v20.11.9/etc/slurm.conf
注:如果在一些安装步骤忘记修改主机名称,可能会出现slurmctld启动失败的情况,通常错误为:error: This host(master) not a valid controller可以将slurm.conf中的ControllerMachine修改成主机名称即可(master)
3.3.2 compute节点的安装
因为是计算节点,compute节点只需要启动slurmd即可
#将 master 节点的slurm安装包传输到 compute 节点(这一条在master执行,compute可以改成自己的主机名字)
scp ~/slurm-20.11.9.tar.bz2 compute:/root
#在compute节点执行解压
tar -jxf slurm-20.11.9.tar.bz2
cd slurm-20.11.9
#配置
export PREFIX=/opt/slurm/v20.11.9
./configure --prefix=$PREFIX
#构建、安装
make && make install
#新建$PREFIX/etc/目录
mkdir -p $PREFIX/etc/
#将master etc目录下的slurm.conf、cgroup.conf文件拷贝到compute节点/opt/slurm/v20.11.9/etc目录(在master节点执行)
scp /opt/slurm/v20.11.9/etc/slurm.conf compute:/opt/slurm/v20.11.9/etc/
scp /opt/slurm/v20.11.9/etc/cgroup.conf compute:/opt/slurm/v20.11.9/etc/
#将etc目录下的slurmd.service文件拷贝到/usr/lib/systemd/system/目录
cp etc/slurmd.service /usr/lib/systemd/system
#将slurm的sbin和bin目录添加到PATH
echo -e '#!/bin/bash\nexport SLURM_HOME=/opt/slurm/v20.11.9\nexport PATH=$SLURM_HOME/sbin:$SLURM_HOME/bin:$PATH' >> /etc/profile.d/slurm.sh
source /etc/profile
#创建配置文件中的目录
mkdir -p $PREFIX/var/spool
chmod 0755 $PREFIX/var/spool
chown -R slurm:slurm $PREFIX/var/spool
mkdir -p $PREFIX/var/run
mkdir -p $PREFIX/var/log
#修改/opt/slurm/v20.11.9/etc/slurm.conf文件,将当前主机配置(slurmd -C)替换到倒数第二行
#如果master节点已经向slurm.conf里添加配置,执行下面命令
sed -i "/PartitionName/i$(slurmd -C | head -n 1)" $PREFIX/etc/slurm.conf
#所有节点的slurm.conf需要保持一致,所以,需要将修改后的slurm.conf拷贝到master节点
#在compute节点执行
scp $PREFIX/etc/slurm.conf master:/$PREFIX/etc/slurm.conf
#启动slurmd服务
systemctl daemon-reload
systemctl enable slurmd --now
#检查服务是否健康
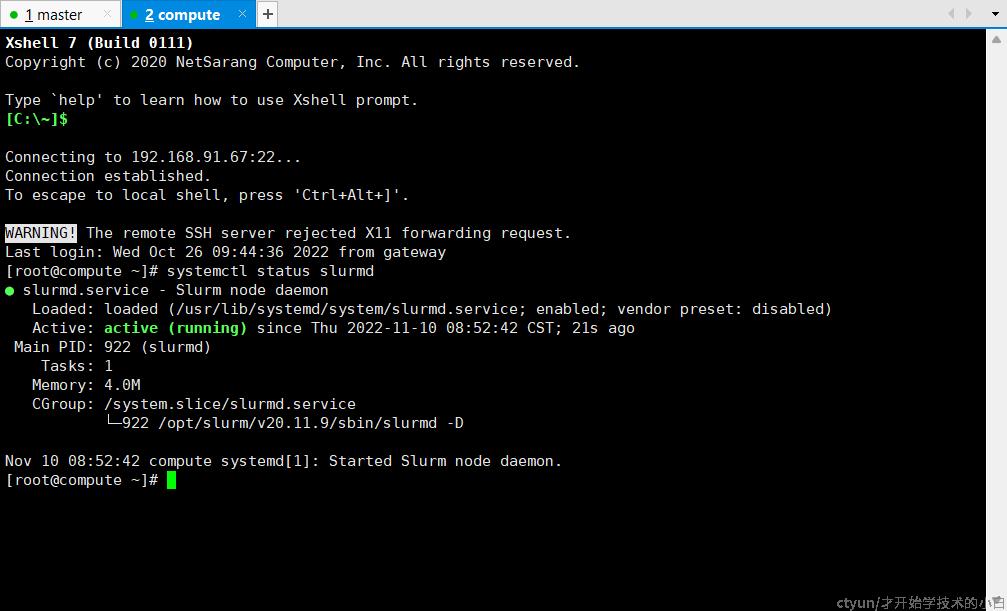
systemctl status slurmd
#因为master节点的slurm.conf更新了,所以需要重启master节点的服务
systemctl restart slurmdbd slurmrestd slurmd slurmctldCompute节点slurmd服务安装成功:
4.验证slurm集群
4.1 集群状态
#在任意节点执行,可以查看分区、节点数、节点状态等
sinfo
#如果有节点为down,可以执行,即变为idle(空闲)状态
scontrol update NodeName=compute State=RESUME
#查看更详细的信息
scontrol show node如果在master节点执行sinfo,出现如下输出:

这说明master节点目前是空闲状态,可以提交作业(注意这是因为本例中我们将master节点也当做compute节点来使用,现实中一般不会这样),如果要将compute从宕机状态回复过来,可以执行:scontrol update NodeName=compute State=RESUME
4.2 作业运行
实际上,slurm支持多种提交作业的方法,如sbatch、salloc、sattach,我们这里只是为了验证slurm集群是否部署成功,因此尝试最简单的srun来提交输出主机名称这一作业。
我们在任意节点执行:srun hostname,指令提交后,系统会自动选择合适的节点执行作业(也可以通过其他一些高级办法手动分配);我们测试的时候这里返回了master,即选择master节点执行作业
如果作业执行时间较长,可以用squeue指令查看作业排队情况;如果已经执行完成,可以使用scontrol show job来查看所有已经执行的任务,如hostname:
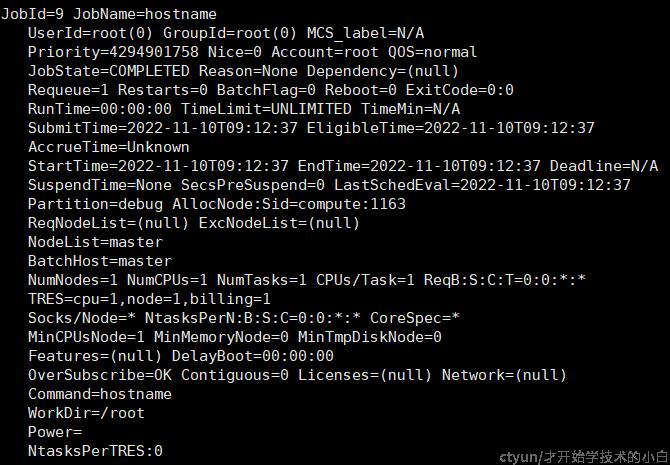
这里的jobid是9,因此也可以使用scontrol show job 9来查看,如果需要清除这些信息,使用scancel 9指令即可
5.总结
以上就是本文的全部内容。参考文章内容,入门HPC领域的初学者可以对节点部署、资源调度、作业提交等有更深入的理解。关于slurm的进一步用法、HPC相关的更多知识,我们会在未来持续更新。
