


NoSQL数据库原理与应用
1. 绪论
1.1 数据库系统
数据库技术是研究数据库的结构、存储、设计、管理和使用的一门科学。
数据库系统的组成:
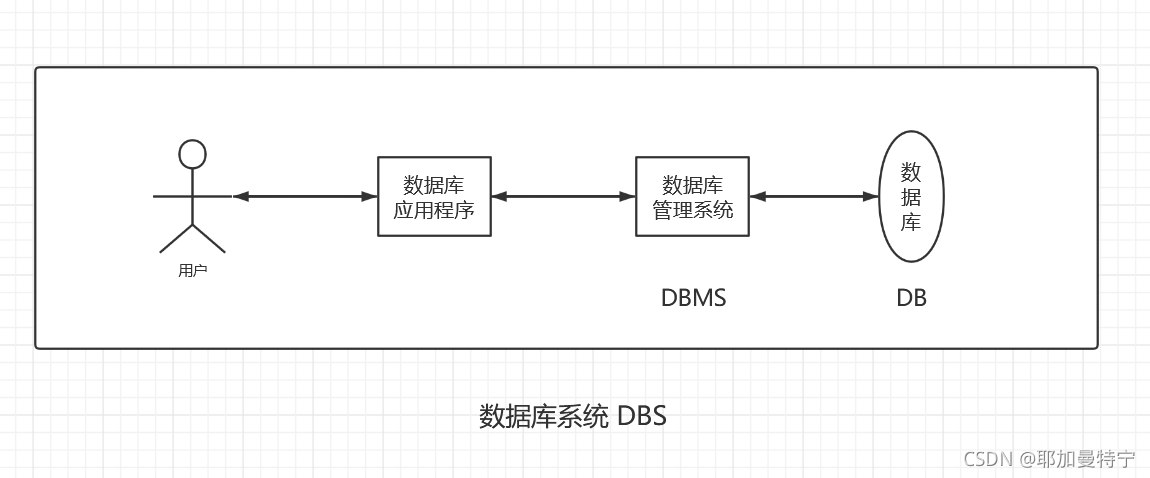
数据库根据不同逻辑模型(一种数据模型)可分为:层次型(一对多)、网状型(多对多)、关系型(二维表)。
数据库管理系统(DBMS)
是一种操纵和管理数据库的大型软件,如Oracle、MySQL都是 DBMS。
是数据库系统的核心。
主要功能有:数据定义 DDL,数据操纵 DML,数据库的运行管理,数据组织、存储与管理,数据库的维护,通信。
数据库应用程序将用户的操作交给 DBMS,再由 DBMS 将其转化为数据库能识别的 DDL(数据定义语言)。
1.2 关系型数据库
关系型数据库以行和列的形式存储数据,这一系列的行和列被称为表
结构化查询语言 SQL:
是关系型数据库的核心。
是一种高度非过程化的语言。
组成:

关系型数据库的优点
容易理解:采用二维表的形式进行存储。
使用方便:使用通用的 SQL 语言进行数据操纵。
易于维护:具有完整性和一致性的特点
完整性:实体完整性、参照完整性、用户自定义完整性
提供对事务的支持,事物的重要特性:原子性要么全完 成,要么全部完成,–> 回滚,保证了数据的一致性。
关系型数据库的缺点
高并发读写能力差
对海量数据的读写效率低
扩展性差(纵向扩展)
由于关系型数据库具有数据模型、完整性约束和事务的强一致性等特点,导致其难以实现高效率的、易横向扩展的分布式架构。
1.3 NoSQL数据库
NoSQL是非关系型数据库的统称。

NoSQL从诞生之初就是分布式、横向扩展的。
特点:
具有灵活的数据模型:可以快速容纳新的数据类型而无需修改表。
可伸缩性强:是分布式、横向扩展的,当数据库服务器无法满足数据存储和数据访问的需求时,只需要增加多台服务器,将用户请求分散到多台服务器上,即可减少单台服务器的性能瓶颈出现的可能性。
自动分片:横向扩展,即增加服务器而不是扩展单台服务器的处理能力。关系型数据库存储的是结构化的数据,采用的是纵向扩展,需要单台服务器持有整个数据库来确保可靠性和数据的持续可用性。
自动复制:服务器会自动对数据进行备份,即将一份数据复制存储在多台服务器上。
关系型数据库和非关系型数据库的区别

1.4 分布式数据库的数据管理
分布式系统的核心理念是让多台服务器协同工作,完成单台服务器无法处理的任务,尤其是高并发或者大数据量的任务。
与传统的关系型数据库相比:
放松事务一致性的要求。
改变固有的表结构。
去除事务、关联等复杂操作。
分布式数据库的特征:
**高扩展性:**分布式数据库必须具有高可扩展性,能够动态地增添存储节点以实现存储容量的线性扩展。
**高并发性:**分布式数据库必须及时响应大规模用户的读/写请求,能对海量数据进行随机读写。
**高可用性:**分布式数据库必须提供容错机制,能够实现对数据的冗余备份,保证数据和服务的高度可靠性。
数据处理方式:集中式 VS 分布式
集中式数据库是指数据库中的数据集中存储在一台计算机上,数据的处理也集中在一台机器上完成。
分布式数据库是指利用高速计算机网络将物理上分散的多个数据存储单元连接起来组成一个逻辑上统一的数据库。
技术管理和主要策略
数据分片/数据分块 --> 多表联合查询性能较差
数据多副本
一次写入多次读取 WORM --> 顺序存储结构,速度较快
分布式系统的可伸缩性
集群状态维护
数据平衡
高可用性
▷ 扩展:数据处理过程
数据采集
数据存储(以xx形式,如二维表,键值,列族,文档,图形)
数据处理和管理
数据可视化
1.5 分布式数据库的理论
1.5.1 CAP理论
一致性(Consistency)、可用性(Availability)和分区容错性(Partition Tolerance)三者无法在分布式系统中被同时满足,并且最多只能满足其中两个。
C : 一致性(consistency)(强一致性)
它是指任何一个读操作总是能够读到之前完成的写操作的结果。所有节点在同一时间具有相同的数据。
A : 可用性(Availability)(高可用性)
每个请求都能在确定时间内返回一个响应,无论请求是成功或失败。
P : 分区容忍性(Partition Tolerance)
它是指分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务。可视为在系统中采用多副本策略。
当处理CAP的问题时,可以有几个明显的选择:
CA 也就是强调一致性(C)和可用性(A),放弃分区容忍性(P),最简单的做法是把所有与事务相关的内容都放到同一台机器上。
CP 也就是强调一致性(C)和分区容忍性(P),放弃可用性(A),当出现网络分区的情况时,受影响的服务需要等待数据一致,因此在等待期间就无法对外提供服务。
**AP ** 也就是强调可用性(A)和分区容忍性(P),放弃一致性(C),允许系统返回不一致的数据。
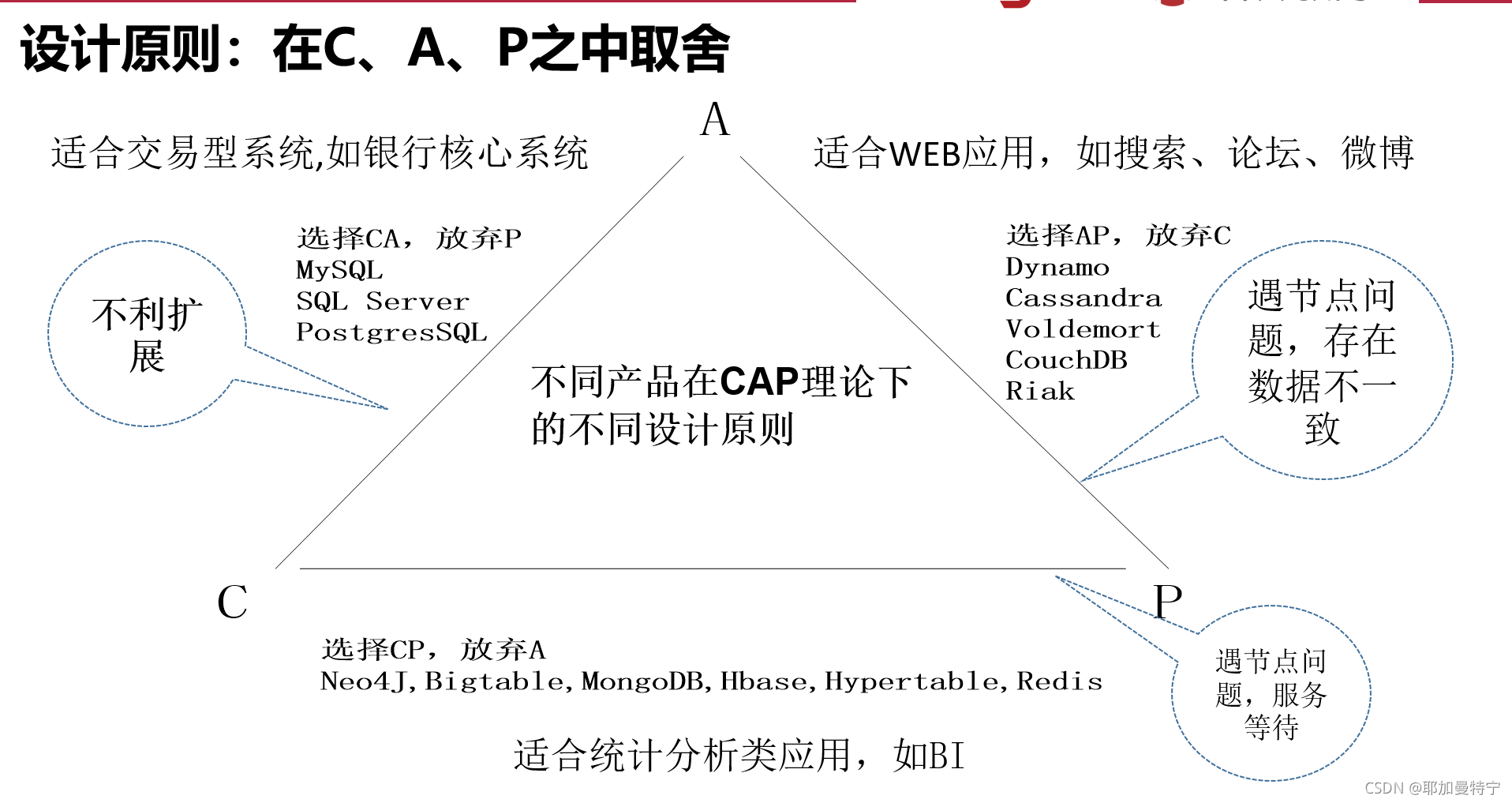
重新理解:三者之间不是非此即彼,应看做连续互相影响,因此可以采用如下策略:绝大多数未分区的情况下,尽可能保证CA,当发生网络分区时,系统应能识别P状况,降低CA并进行相应处理。
1.5.2 BASE理论
ACID
**事务:**是一个一致和可靠计算的基本单元,由作为原子单元执行的一系列数据库操作组成。数据库一般在启动时会提供事务机制,包括事务启动、停止、取消或回滚等。
ACID 是对 CAP 中的强一致性(C)和可用性(A)进行权衡的结果。
ACID 指数据库事务正确执行的四个基本要素的缩写。包含:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。
**原子性:**一个事务的所有系列操作步骤被看成是一个动作,所有 的步骤要么全部完成要么都不会完成。
**一致性:**事务执行前后,数据库的状态都满足所有的完整性约 束。不能发生表与表之间存在外键约束,但是有数据却违背这种约束性。
隔离性:并发执行的事务是隔离的,保证多个事务互不影响,隔离能够确保并发执行的事务能够顺序一个接一个执行,通过隔离,一个未完成事务不会影响另外一个未完成事务。
**持久性:**一个事务一旦提交,它对数据库中数据的改变就应该是永久性的,不会因为和其他操作冲突而取消这个事务。
BASE
BASE 是对 CAP 中的弱一致性(C)和可用性(A)进行权衡的结果。
**核心思想:**无法做到强一致性,但每个应用都可以根据自身的特点,采用适当方式达到最终一致性。
BASE原则 = 基本可用性(Basically Available) + 软状态(Soft state) + 最终一致性(Eventuallyconsistent)
**基本可用性:**分布式系统在出现故障的时候,允许损失部分可用性,即保证核心功能或者当前最重要功能可用,但是其他功能会被削弱。
**软状态:**允许系统数据存在中间状态,但不会影响到系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步时存在延时(暂时不一致)。
**最终一致性(核心):**要求系统数据副本最终能够一致,而不需要实时保证数据副本一致。*最终一致性是弱一致性的一种特殊情况。
BASE理论和ACID理论的区别

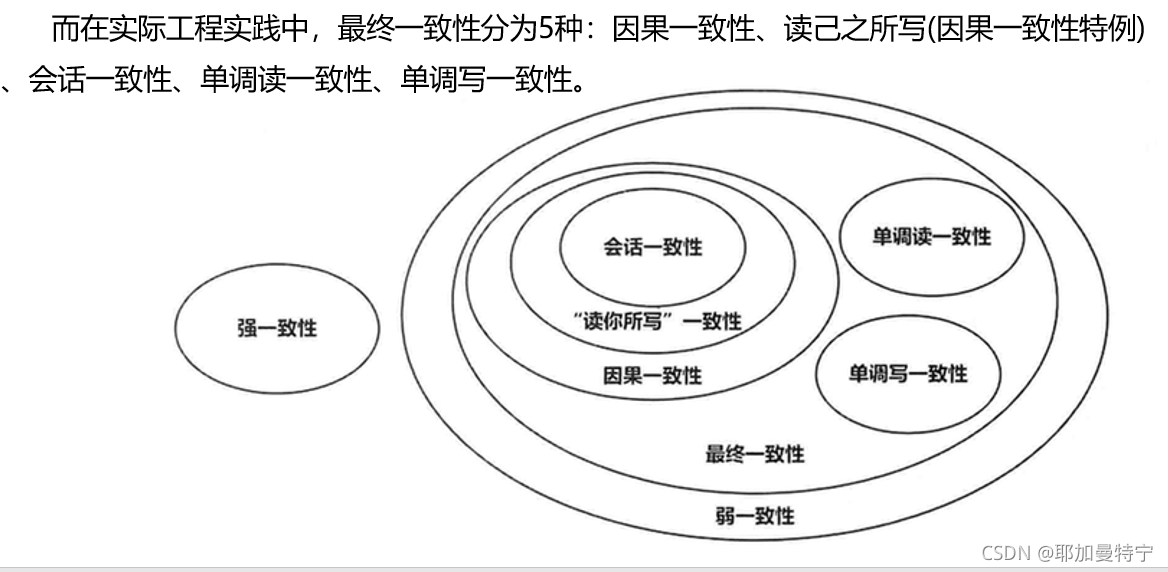
1.5.3 最终一致性
最终一致性是 BASE 原理的核心,也是 NoSQL 数据库的主要特点,通过弱化一致性,提高系统的可伸缩性、可靠性和可用性。
牺牲一致性换取高可用性是多数分布式数据库产品的方向。
五个变种:
实现一致性的策略 --> NRW策略
三个关键字N、R、W。
N — 数据复制的份数
W — 更新数据时需要保证写完成的节点数
R — 读取数据时需要保证读完成的节点数
如果W+R>N,写的节点和读的节点重叠,则是强一致性。
如果W+R<=N,不能保证读写有重叠,则是弱一致性
不同的N,W,R组合,是在可用性和一致性之间取一个平衡
总体上看,一致性和可用性成负相关。
1.6 NoSQL 数据库分类
NoSQL 是基于存储的数据结构进行分类的。

2. HBase
2.1 HBase简介
HBase 是一个分布式非关系型数据库。
既可以存储结构化数据,也可以存储非结构化数据或半结构化数据。
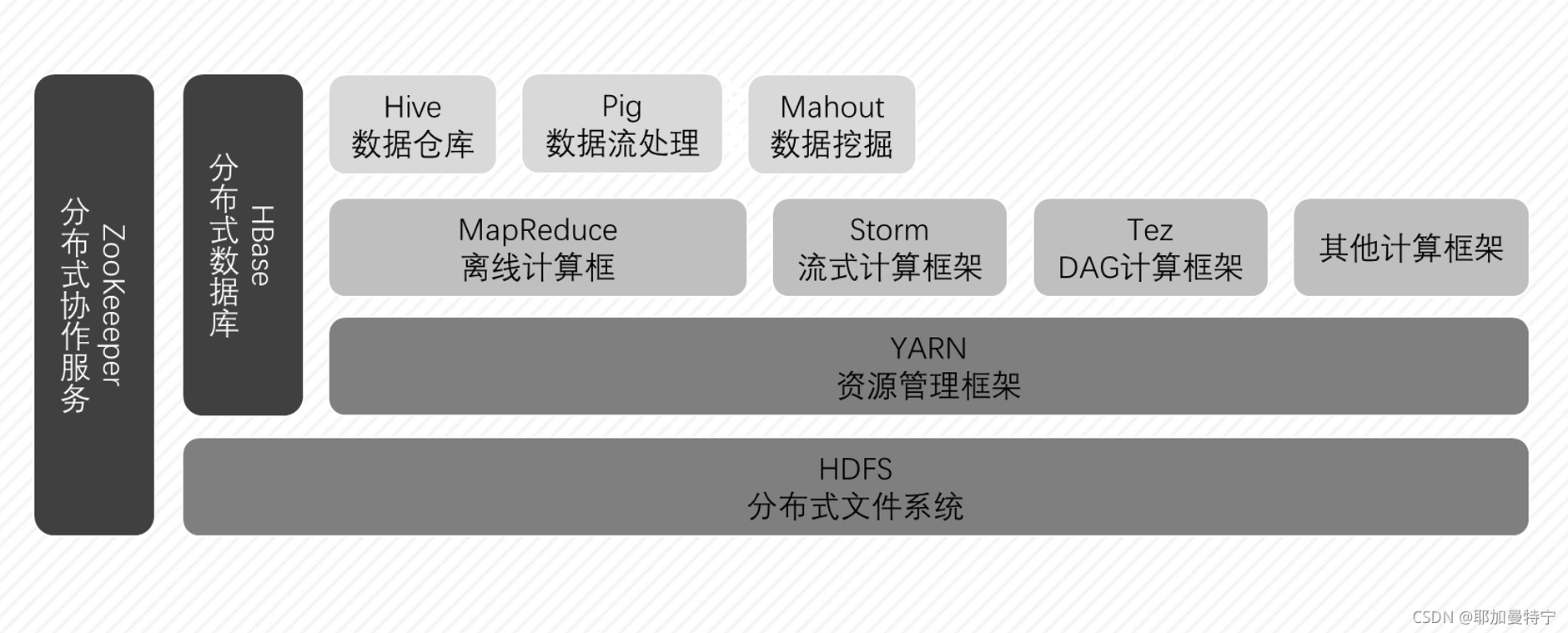
使用 Java 语言实现,底层基于Hadoop 的 HDFS 来存储数据,在此基础上运行 MapReduce 进行分布式的批量处理数据,为 Hadoop 提供海量数据管理的服务。
是 Apache 基金会的 Hadoop 项目的一部分;是对 Google 的 Bigtable 的开源实现。
HBase 特性:
容量巨大
列存储
稀疏性
扩展型强
高可靠性
HBase 和 Hadoop
2.2 HBase 的组件及其功能
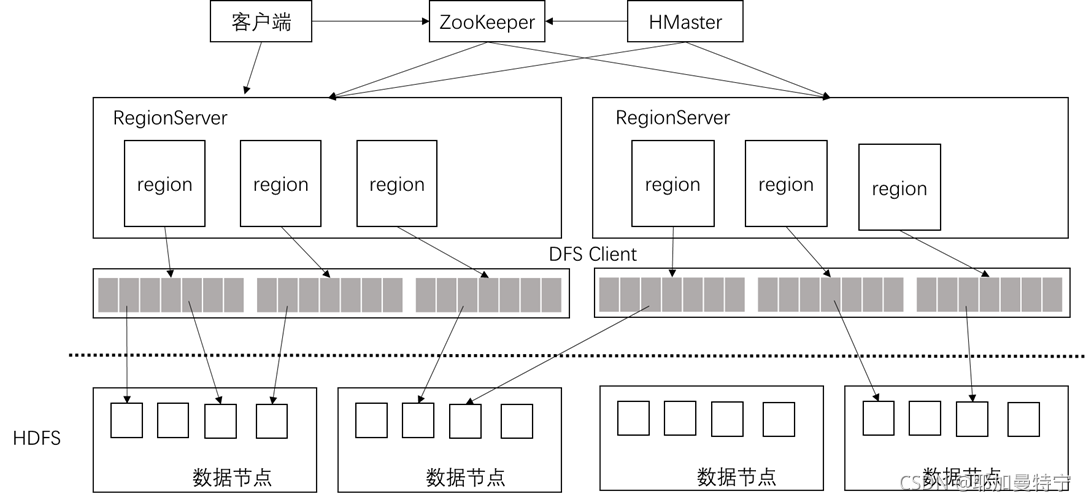
HBase 的系统架构包括客户端、ZooKeeper 服务器、HMaster 主服务器和RegionServer。
客户端
HBase系统的入口 --> 操作HBase
通信功能(RPC机制):与HMaster进行管理类通信,与Regionserver进行数据读写操作。
支持多种形式:HBase shell、Java、Thrift等
ZooKeeper
ZooKeeper 是一个高性能、集中化、分布式应用程序协调服务,主要是用来解决分布式应用中用户经常遇到的一些数据管理问题。
ZooKeeper 是串联 HBase 集群和 Client 的关键。
负责协调的任务:
HMaster选举(最典型的应用场景)
HBase集群中有多个 HMaster 并存,通过竞争选举机制保证同一时刻只有一个 HMaster 处于活跃状态。
类似于 HDFS 的 HA 机制:只有一个 NameNode 处于活跃状态
系统容错
维护元数据,记录HMaster节点地址
Region状态管理
HMaster
HMaster是 HBase 集群中的主服务器,负责监控集群中的所有RegionServer,并且是所有元数据更改的接口.
HMaster 服务器通常运行在 HDFS 的 NameNode 上,HMaster 通过Zookeeper 来避免单点故障
HMaster主要负责表和region的管理工作:
(1)管理用户对表的增、删、改、查操作
(2)管理RegionServer的负载均衡,调整region的分布。
(3)Region的分配和移除
(4)处理RegionServer的故障转移。
HMaster故障不影响当前客户端对数据的访问,因为客户端直接与 RegionServer交互。但需尽快恢复,避免后续操作的正确性。
RegionServer
RegionServer主要负责响应用户的请求,向HDFS中读写数据。
一般在分布式集群当中,RegionServer运行在DataNode服务器上,实现数据的本地性。
RegionServer 是 HBase 中最核心的模块,其内部管理了一系列 Region 对象,每个 Region 由多个 HStore 组成,每个Hstore 对应表中的一个列族的存储。
RegionServer 的功能:
(1)处理客户端读写请求。
(2)处理分批给它的region。
(3)刷新缓存到HDFS中。
(4)处理region的合并和分片。
2.3 HBase数据模型
2.4 HBase Shell
————————————————
版权声明:本文为CSDN博主「耶加曼特宁」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_49990067/article/details/120377355
