


基本概念
什么是NoSQL?
NoSQL是一些分布式非关系型数据库的统称,它采用非关系的数据模型,弱化模式或表结构、弱化完整性约束、弱化甚至取消事务机制,可能无法支持,或不能完整的支持SQL语句。
目的是实现强大的分布式部署能力——一般包括分区容错性、伸缩性和访问效率(可用性)。
什么是HBase?
全称Hadoop Database,它是Google BigTable的开源实现,是一个高可靠、高性能、可伸缩、实时读写、列式存储的分布式NoSQL数据库。所以,它与Hive不同的是,它更适合存储非结构化、半结构化数据,其次是完全的列式存储,并且支持实时读写;当然它们都是分布式的大数据产品,就一定支持集群的动态伸缩、可靠性高、性能优异的特点。

HBase数据以Key-Value形式存储,以二维表方式组织,所以对于HBase表的操作,和关系型数据库的数据表有些类似,但底层存储形式截然不同;而且HBase只能通过API操作,不支持SQL。
Hbase更适合存储半结构化、非结构化数据。当然HBase也支持结构化数据存储,但相对于关系型数据库而言,它们的侧重点有所不同。关系型数据库更侧重于小规模数据的在线事务处理(OLTP),而HBase侧重于海量数据的实时读写。
HBase底层采用HDFS作为文件存储系统,数据的可靠性由HDFS来保证。
HBase特点
1.海量数据存储:HBase作为大数据NoSQL数据库,能够存储PB级别以上的数据;而且因为底层是以Key-Value形式存储,不支持SQL,所以更适合非结构化、半结构化数据存储。
2.列式存储:在大数据领域,列式存储可以更好的提升性能,因为减少了数据量的抽取。例如在单独对某几列数据进行运算时,如果是基于行式存储,则需要将表中的每行数据读取到内存中,然后再对需要的列数据进行抽取,而列式存储则直接将需要的列加载到内存中即可;这在海量数据的背景中,对性能有质的提升。
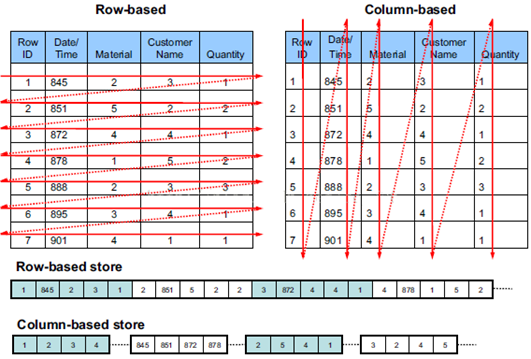
3.稀疏性:正因为列式存储的方式,所以HBase允许数据的稀疏存储,即值为空的数据不占用存储空间。对于行式存储,因为每行数据的大小是固定的,所以即使某一行的某个字段,数据为空,也必须使用占位符代替;但列式存储而言,每一列数据存放在一起,且对每列数据单独建立索引,如果某个字段数据为空,则可以不进行存储,没有行式存储的限制。列式存储带来的稀疏性,在海量数据背景下,对磁盘空间的利用率有了很大提升。
4.数据实时随机读写:虽然HBase数据存储在HDFS中,但它作为一个数据库而言,使用LSM树,将数据缓存到内存中,可以保证数据进行实时的读写,缓存达到阈值后才会存储到HDFS中。可是HDFS并不支持对数据进行修改,HBase其实将数据的修改操作,转换为了追加操作,将修改后的数据打上时间戳,这样在读取数据时,只获取最新时间戳的数据即可;这样的话,数据冗余就会越来越多,HBase会定期将HDFS中的数据进行合并,删除过期数据。
5.数据强一致性:数据一致更新,所有数据变动都是同步的,这里的同步是指客户端和服务端两个层面。这样就意味着,数据一旦写入到HBase中,所有的客户端看到的数据都是最新的,HBase服务端集群中的各个节点保存的数据也是最新的。因为,虽然HBase的数据是分布在不同节点中的,但对于某一条特定的数据,一定是位于某一个从节点中的;只要这个节点的数据更新后,意味着之后的访问都可以获取到最新数据;那在分布式集群中,这个从节点宕机怎么办?数据可靠性如何保证?HBase的数据最终是存储到HDFS中的,而HDFS有副本机制可以保证,而HBase则不需要关心数据的可靠性。
6.高并发、高可靠、高扩展:首先HBase是高并发的,主要面向高并发读,可以支持多用户查询,这也是它的应用场景之一;其次在大数据产品中,高可靠、高扩展是它必须具备的两个特性,保证服务是可靠的,是容灾的,而且集群要随着数据和处理规模的变化,进行动态的扩缩容。
所以,总结起来,HBase作为一个存储系统,必然能够进行海量数据的存储;对于这些存储起来的海量数据,因为它的列式存储特性,抽取的数据量减少,处理性能有了很大的提升,而且列式存储直接带来了稀疏的特性,提升磁盘利用率。其次,HBase作为数据库,能够满足数据的实时随机读写,并提供数据强一致性保证。最后,它作为大数据系统,有高可靠、高扩展的特性,并且具有高并发的优势。
适用场景

一般在企业生产中,会在以下4个场景中使用HBase。
1.实时读写:因为HBase本身使用缓存机制,数据立即写入缓存之后,客户端便可以立即从缓存中进行读取,并且有数据强一致性的保证,这是像Hive这类专门用于数据批处理的产品所无法提供的。所以,HBase一般会用于实时流处理场景中,对结果数据,或者中间数据进行存储;流处理场景的数据实时性很高,当前数据的处理结果要实时写入,并且写入后要立即能够满足下一批到达的数据进行读取,这都是HBase可以提供的特性。
2.并发查询:如果在海量数据场景中,有高并发查询的要求,比如需要保证1000人同时进行数据查询,那一定会考虑HBase。但要注意,只能满足简单条件的查询,因为HBase只有单个主键(RowKey),而对于其它字段进行条件查询时均会进行全表扫描,所以对于RowKey的优化是HBase性能提升的关键,这也是为什么HBase在复杂查询场景中性能不好的原因。
3.半结构化和非结构化数据存储:HBase本身是NoSQL数据库,不像关系型数据库一样有多种数据类型,它所有的数据都是字节数组Byte[],所以能够满足半结构化、非结构化数据的存储,如JSON、日志、图片、音频的存储。对于小于100K的数据,HBase有较好的优化,对于100K-10M的数据,则需要开启MOB功能(这里先留个印象),超过10M的文件,性能上会有折损。
4.动态DDL结构化数据存储:HBase虽然本质是Key-Value数据库,但它使用二维表的形式进行组织,所以也可以用于存储结构化数据。而且因为HBase列式存储的特性,所以表字段的变化对数据不造成影响,比如对表临时增加一个字段、删除一个字段,而在行式存储的数据库中,会造成很大的性能影响。这也就使得HBase极其适合表结构动态变化的场景,适应频繁的DDL操作,这在互联网场景业务不确定的情况下会有很大的帮助。
访问方式

HBase可以使用Shell命令直接进行操作,它和SQL语法不同,需要一定的学习成本,这是使用最多的一种方式。但如果集成了Apache Phoenix,则支持在HBase上直接使用SQL进行操作,Phoenix会自动完成转换操作,这种方式学习成本低,易用性强,很受企业开发者的青睐。当然对于开发人员,HBase也提供编程接口HBase API,来完成对HBase的操作。
基本对HBase有一个认识后,接下来学习一下HBase的数据模型和系统架构的内容。
————————————————
版权声明:本文为CSDN博主「桥路丶」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_33876553/article/details/120634051
