


一、人脸图像特征提取方法简介
HOG特征提取步骤
(1)输入图像并检测窗口
将目标图片输入并在视窗检测图片
(2)伽马与色彩归一化
为了减少光照因素的影响,首先需要将整个图像进行规范化(归一化)。在图像的纹理强度中,局部的表层曝光贡献的比重较大,所以,这种压缩处理能够有效地降低图像局部的阴影和光照变化。
(3)计算梯度
计算图像横坐标和纵坐标方向的梯度,并据此计算每个像素位置的梯度方向值;求导操作不仅能够捕获轮廓,人影和一些纹理信息,还能进一步弱化光照的影响。
最常用的方法是:简单地使用一个一维的离散微分模板在一个方向上或者同时在水平和垂直两个方向上对图像进行处理,更确切地说,这个方法需要使用滤波器核滤除图像中的色彩或变化剧烈的数据
(4)构造方向直方图
细胞单元中的每一个像素点都为某个基于方向的直方图通道投票。投票是采取加权投票的方式,即每一票都是带有权值的,这个权值是根据该像素点的梯度幅度计算出来。可以采用幅值本身或者它的函数来表示这个权值,实际测试表明: 使用幅值来表示权值能获得最佳的效果,当然,也可以选择幅值的函数来表示,比如幅值的平方根、幅值的平方、幅值的截断形式等。细胞单元可以是矩形的,也可以是星形的。直方图通道是平均分布在0-1800(无向)或0-3600(有向)范围内。经研究发现,采用无向的梯度和9个直方图通道,能在行人检测试验中取得最佳的效果。
(5)合成各细胞单元使区间在空间上连通
把各个细胞单元组合成大的、空间上连通的区间。这样,HOG描述符就变成了由各区间所有细胞单元的直方图成分所组成的一个向量。这些区间是互有重叠的,这就意味着:每一个细胞单元的输出都多次作用于最终的描述器。
(6)HOG特征收集
把提取的HOG特征输入到SVM分类器中,寻找一个最优超平面作为决策函数。
Dlib人脸特征检测
(1)提取特征点
(2)将获取的特征数据集写入csv
(3)计算特征数据集的欧氏距离并做对比
二、笑脸识别
1.下载必备工具及库
下载tensorflow
dlib,Keras均是在Anaconda Prompt窗口下的TensorFlow环境中进行的。
在 Anaconda 中创建 python3.6 版本的TensorFlow环境
在Anaconda Prompt窗口下输入命令
conda create -n tensorflow python=3.6

激活 python3.6 的 tensorflow 环境
activate tensorflow
使用豆瓣镜像安装 tensorflow
pip install tensorflow -i https://pypi.douban.com/simple
激活对应的conda环境
conda activate tensorflow
安装ipykernel
pip install ipykernel -i https://pypi.douban.com/simple
将环境写入notebook的kernel中
python -m ipykernel install --user --name tensorflow --display-name "Python (tensorflow)"
查看是否安装成功
dilb库下载
(根据我的python版本)
下载的dlib.whl文件如下:
dlib-19.7.0-cp36-cp36m-win_amd64.whl

在tensorflow环境下命令下载安装dlib.whl文件

在tensorflow环境下命令下载Keras
pip install keras
2.微笑数据集
运行tensorliow环境之后导包
import keras
keras.__version__
import os
读取训练集的图片,将训练数据和测试数据放入自己创建的文件夹
# The path to the directory where the original
# dataset was uncompressed
riginal_dataset_dir = 'D:\genki4k'
# The directory where we will
# store our smaller dataset
base_dir = 'genki4k'
os.mkdir(base_dir)
# Directories for our training,
# validation and test splits
train_dir = os.path.join(base_dir, 'train')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir, 'validation')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir, 'test')
os.mkdir(test_dir)
# Directory with our training smile pictures
train_smile_dir = os.path.join(train_dir, 'smile')
os.mkdir(train_smile_dir)
# Directory with our training unsmile pictures
train_unsmile_dir = os.path.join(train_dir, 'unsmile')
#s.mkdir(train_dogs_dir)
# Directory with our validation smile pictures
validation_smile_dir = os.path.join(validation_dir, 'smile')
os.mkdir(validation_smile_dir)
# Directory with our validation unsmile pictures
validation_unsmile_dir = os.path.join(validation_dir, 'unsmile')
os.mkdir(validation_unsmile_dir)
# Directory with our validation smile pictures
test_smile_dir = os.path.join(test_dir, 'smile')
os.mkdir(test_smile_dir)
# Directory with our validation unsmile pictures
test_unsmile_dir = os.path.join(test_dir, 'unsmile')
os.mkdir(test_unsmile_dir)
复制图片到文件夹中



(就是把微笑与不微笑的照片放在对应文件夹中)
在jupyter中将文件夹的路径引入
train_smile_dir="genki4k/train/smile/"
train_umsmile_dir="genki4k/train/unsmile/"
test_smile_dir="genki4k/test/smile/"
test_umsmile_dir="genki4k/test/unsmile/"
validation_smile_dir="genki4k/validation/smile/"
validation_unsmile_dir="genki4k/validation/unsmile/"
train_dir="genki4k/train/"
test_dir="genki4k/test/"
validation_dir="genki4k/validation/"
打印文件夹下的图片数量
print('total training smile images:', len(os.listdir(train_smile_dir)))
print('total training unsmile images:', len(os.listdir(train_umsmile_dir)))
print('total testing smile images:', len(os.listdir(test_smile_dir)))
print('total testing unsmile images:', len(os.listdir(test_umsmile_dir)))
print('total validation smile images:', len(os.listdir(validation_smile_dir)))
print('total validation unsmile images:', len(os.listdir(validation_unsmile_dir)))
3.模型创建及归一化处理
模型创建:
#创建模型
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
查看模型:
model.summary()


归一化处理
from keras import optimizers
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
from keras.preprocessing.image import ImageDataGenerator
# All images will be rescaled by 1./255
train_datagen = ImageDataGenerator(rescale=1./255)
validation_datagen=ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
# 目标文件目录
train_dir,
#所有图片的size必须是150x150
target_size=(150, 150),
batch_size=20,
# Since we use binary_crossentropy loss, we need binary labels
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
test_generator = test_datagen.flow_from_directory(test_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
运行后,训练结果显示:

0,1含义:
train_generator.class_indices

4.数据增强
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
import matplotlib.pyplot as plt
# This is module with image preprocessing utilities
from keras.preprocessing import image
fnames = [os.path.join(train_smile_dir, fname) for fname in os.listdir(train_smile_dir)]
img_path = fnames[3]
img = image.load_img(img_path, target_size=(150, 150))
x = image.img_to_array(img)
x = x.reshape((1,) + x.shape)
i = 0
for batch in datagen.flow(x, batch_size=1):
plt.figure(i)
imgplot = plt.imshow(image.array_to_img(batch[0]))
i += 1
if i % 4 == 0:
break
plt.show()



5.创建网络
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
6.模型训练及保存
#归一化处理
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,)
# Note that the validation data should not be augmented!
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
# This is the target directory
train_dir,
# All images will be resized to 150x150
target_size=(150, 150),
batch_size=32,
# Since we use binary_crossentropy loss, we need binary labels
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary')
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=60,
validation_data=validation_generator,
validation_steps=50)
保存模型:
model.save('genki4k/smileORunsmile_2.h5')
1
2
7.图片判别
单张图片判别:
# 单张图片进行判断 是笑脸还是非笑脸
import cv2
from keras.preprocessing import image
from keras.models import load_model
import numpy as np
#加载模型
model = load_model('genki4k/smileORunsmile_2.h5')
#本地图片路径
img_path='genki4k/test/smile/file0901.jpg'
img = image.load_img(img_path, target_size=(150, 150))
img_tensor = image.img_to_array(img)/255.0
img_tensor = np.expand_dims(img_tensor, axis=0)
prediction =model.predict(img_tensor)
print(prediction)
if prediction[0][0]>0.5:
result='非笑脸'
else:
result='笑脸'
print(result)


8.人脸识别
import cv2
from keras.preprocessing import image
from keras.models import load_model
import numpy as np
import dlib
from PIL import Image
model = load_model('genki4k/smileORunsmile_2.h5')
detector = dlib.get_frontal_face_detector()
video=cv2.VideoCapture(0)
font = cv2.FONT_HERSHEY_SIMPLEX
def rec(img):
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
dets=detector(gray,1)
if dets is not None:
for face in dets:
left=face.left()
top=face.top()
right=face.right()
bottom=face.bottom()
cv2.rectangle(img,(left,top),(right,bottom),(0,255,0),2)
img1=cv2.resize(img[top:bottom,left:right],dsize=(150,150))
img1=cv2.cvtColor(img1,cv2.COLOR_BGR2RGB)
img1 = np.array(img1)/255.
img_tensor = img1.reshape(-1,150,150,3)
prediction =model.predict(img_tensor)
print(prediction)
if prediction[0][0]>0.5:
result='unsmile'
else:
result='smile'
cv2.putText(img, result, (left,top), font, 2, (0, 255, 0), 2, cv2.LINE_AA)
cv2.imshow('Video', img)
while video.isOpened():
res, img_rd = video.read()
if not res:
break
rec(img_rd)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
video.release()
cv2.destroyAllWindows()


三、口罩识别
1.口罩数据集
运行TensorFlow环境并导入包
import keras
Import os,shutil
读取训练集的图片,将训练数据和测试数据放入自己创建的文件夹
# The path to the directory where the original
# dataset was uncompressed
riginal_dataset_dir = 'D:\mask'
# The directory where we will
# store our smaller dataset
base_dir = 'mask'
os.mkdir(base_dir)
# Directories for our training,
# validation and test splits
train_dir = os.path.join(base_dir, 'train')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir, 'validation')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir, 'test')
os.mkdir(test_dir)
# Directory with our training smile pictures
train_mask_dir = os.path.join(train_dir, 'mask')
os.mkdir(train_mask_dir)
# Directory with our training unsmile pictures
train_unmask_dir = os.path.join(train_dir, 'unmask')
os.mkdir(train_unmask_dir)
#s.mkdir(train_dogs_dir)
# Directory with our validation smile pictures
validation_mask_dir = os.path.join(validation_dir, 'mask')
os.mkdir(validation_mask_dir)
# Directory with our validation unsmile pictures
validation_unmask_dir = os.path.join(validation_dir, 'unmask')
os.mkdir(validation_unmask_dir)
# Directory with our validation smile pictures
test_mask_dir = os.path.join(test_dir, 'mask')
os.mkdir(test_mask_dir)
# Directory with our validation unsmile pictures
test_unmask_dir = os.path.join(test_dir, 'unmask')
os.mkdir(test_unmask_dir)
复制图片到文件夹中

在jupyter中将文件夹的路径引入
train_mask_dir="mask/train/mask/"
train_unmask_dir="mask/train/unmask/"
test_mask_dir="mask/test/mask/"
test_unmask_dir="mask/test/unmask/"
validation_mask_dir="mask/validation/mask/"
validation_unmask_dir="mask/validation/unmask/"
train_dir="mask/train/"
test_dir="mask/test/"
validation_dir="mask/validation/"
打印文件夹下的图片数量
print('total training mask images:', len(os.listdir(train_mask_dir)))
print('total training unmask images:', len(os.listdir(train_unmask_dir)))
print('total testing mask images:', len(os.listdir(test_mask_dir)))
print('total testing unmask images:', len(os.listdir(test_unmask_dir)))
print('total validation mask images:', len(os.listdir(validation_mask_dir)))
print('total validation unmask images:', len(os.listdir(validation_unmask_dir)))
2.模型创建及归一化处理
模型创建
#创建模型
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
归一化处理
from keras import optimizers
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
from keras.preprocessing.image import ImageDataGenerator
# All images will be rescaled by 1./255
train_datagen = ImageDataGenerator(rescale=1./255)
validation_datagen=ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
# 目标文件目录
train_dir,
#所有图片的size必须是150x150
target_size=(150, 150),
batch_size=20,
# Since we use binary_crossentropy loss, we need binary labels
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
test_generator = test_datagen.flow_from_directory(test_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
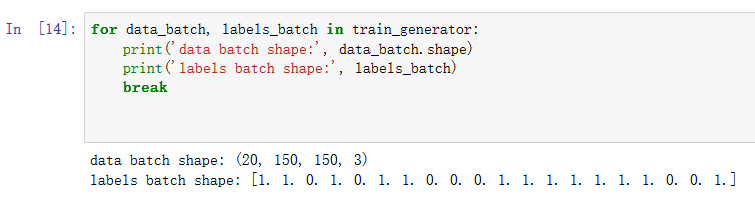
for data_batch, labels_batch in train_generator:
print('data batch shape:', data_batch.shape)
print('labels batch shape:', labels_batch.shape)
break
train_generator.class_indices

3.数据增强
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
import matplotlib.pyplot as plt
from keras.preprocessing import image
fnames = [os.path.join(train_mask_dir, fname) for fname in os.listdir(train_mask_dir)]
img_path = fnames[3]
img = image.load_img(img_path, target_size=(150, 150))
x = image.img_to_array(img)
x = x.reshape((1,) + x.shape)
i = 0
for batch in datagen.flow(x, batch_size=1):
plt.figure(i)
imgplot = plt.imshow(image.array_to_img(batch[0]))
i += 1
if i % 4 == 0:
break
plt.show()
4.创建网络
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
5.模型训练及保存
模型训练:
#花费时间长
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=10,
validation_data=validation_generator,
validation_steps=50)
保存模型:
#保存模型
model.save('mask/maskORunmask_1.h5')
6.图片判别
单张图片判别
# 单张图片进行判断 是否戴口罩
import cv2
from keras.preprocessing import image
from keras.models import load_model
import numpy as np
model = load_model('mask/maskORunmask_2.h5')
img_path='mask/test/unmask/file0791.jpg'
img = image.load_img(img_path, target_size=(150, 150))
#print(img.size)
img_tensor = image.img_to_array(img)/255.0
img_tensor = np.expand_dims(img_tensor, axis=0)
prediction =model.predict(img_tensor)
print(prediction)
if prediction[0][0]>0.5:
result='未戴口罩'
else:
result='戴口罩'
print(result)



7.人脸识别
摄像头采集人脸识别
import cv2
from keras.preprocessing import image
from keras.models import load_model
import numpy as np
import dlib
from PIL import Image
model = load_model('genki4k/smileORunsmile_2.h5')
detector = dlib.get_frontal_face_detector()
video=cv2.VideoCapture(0)
font = cv2.FONT_HERSHEY_SIMPLEX
def rec(img):
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
dets=detector(gray,1)
if dets is not None:
for face in dets:
left=face.left()
top=face.top()
right=face.right()
bottom=face.bottom()
cv2.rectangle(img,(left,top),(right,bottom),(0,255,0),2)
img1=cv2.resize(img[top:bottom,left:right],dsize=(150,150))
img1=cv2.cvtColor(img1,cv2.COLOR_BGR2RGB)
img1 = np.array(img1)/255.
img_tensor = img1.reshape(-1,150,150,3)
prediction =model.predict(img_tensor)
print(prediction)
if prediction[0][0]>0.5:
result='unsmile'
else:
result='smile'
cv2.putText(img, result, (left,top), font, 2, (0, 255, 0), 2, cv2.LINE_AA)
cv2.imshow('Video', img)
while video.isOpened():
res, img_rd = video.read()
if not res:
break
rec(img_rd)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
video.release()
cv2.destroyAllWindows()


————————————————
版权声明:本文为CSDN博主「sillystar」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/sillystar/article/details/107206482
